深度学习:玩转caffe之安装
Caffe安装初探
引言
做深度学习,没用玩过深度学习框架caffe就有点说不过去了。虽然自己的小机器显卡计算能力很弱,但是希望在cuda上跑caffe的心却没有停止过。从ubuntu12.04一直折腾到16.04,cuda从6.5也release到了8.0,中间走过的弯路很多。 - cuda与系统的适配能力问题 - ubuntu系统的问题 - caffe的框架的问题 经过这几年的发展,现在caffe的安装已经变得异常简单便捷。在此记录一下曾经的坑。 建议: 直接在机器上安装linux进行下面操作,要是在虚拟机里整,几乎没有什么戏,而且会把你给整疯的。
安装BLAS
BLAS 可以通过mkl atlas openblas等实现,性能比较 发现这个mkl是不错的,但是要收费 最后选择默认的Atlas
********** Important Install Information: CPU THROTTLING ***********
Architecture configured as Corei2 (27) /tmp/ccp8Kkgo.o: In function
ATL_tmpnam': /home/charles/Repo/ATLAS//CONFIG/include/atlas_sys.h:224: warning: the use oftmpnam'
is dangerous, better use `mkstemp'
Clock rate configured as 800Mhz
Maximum number of threads configured as 4
probe_pmake.o: In function `ATL_tmpnam':
/home/charles/Repo/ATLAS//CONFIG/include/atlas_sys.h:224: warning: the use of `tmpnam` is dangerous, better use `mkstemp`
Parallel make command configured as '$(MAKE) -j 4'
CPU Throttling apparently enabled!
It appears you have cpu throttling enabled, which makes timings
unreliable and an ATLAS install nonsensical. Aborting.
See ATLAS/INSTALL.txt for further information
xconfig exited with 1******************************* Solution *************************** use ubuntu main software source switch to root admin
apt-get install gnome-applets cpufreq-selector -g performance -c 0
sudo apt-get install libatlas-base-dev
安装BOOST
- preinstall boost should install following software
- compile the source code 下载源代码,当前最新版本为version 1.60
1 | wget http://downloads.sourceforge.net/project/boost/boost/1.60.0/boost_1_60_0.tar.gz |
1 |
|
或者直接apt-get install libboost-all-dev
从7.5之后安装的方法简单得多
sudo apt-get --purge remove nvidia-*
到https://developer.nvidia.com/cuda-downloads下载对应的deb文件
到deb的下载目录下
1 | sudo dpkg -i cuda-repo-ubuntu1404_7.5-18_amd64.deb |
完成,cuda和显卡驱动就都装好了;其他的什么都不用动 而网上大部分中文和英文的参考教程都是过时的,折腾几个小时不说还容易装不成。
查看机器参数是否满足CUDA计算的最低要求
1 | lspci | grep -i nvidia |
参照nvidia 往年发布的gpus 我的机器为Compute Capability 2.1,是可以使用CUDA加速的。: )
不是所有Nvida显卡都支持cuDNN的
折腾了很久的cuDNN安装,后来才发现是自己的显卡太low了,不支持cuDNN,因为Compute Capability 才2.1,要支持cuDNN, Capability >= 3.0,查看自己显卡的计算能力
install cuDNN
PREREQUISITES CUDA 7.0 and a GPU of compute capability 3.0 or higher
are required. Extract the cuDNN archive to a directory of your choice,
referred to below as
LINUX
1 | cd <installpath> |
Add
WINDOWS
Add
In your Visual Studio project properties, add
非GPU的自动安装脚本
pyCaffe编译安装
- 首先要编译caffe成功,make pycaffe也成功
- 使得pycaffe可以被访问到, set
PYTHONPATH=$PYTHONPATH:/path/to/caffe/python - install dependencies python
package.在python文件夹下面有requirements.txt文件,列出了所有有关的python
package.
pip install -r requirements.txtNote 这里一定要弄明白,默认情况下是使用python2.x的,如果你使用python3.x的话,请安装python3-pip,使用pip3进行安装,
综合一个安装cuda的教程
可以参考https://gwyve.github.io/博客,为了方便把gwyve的cuda 安装部分blog放到这里。
引言
使用NVIDIA GPU进行dnn目前已经成为了主流,年前就打算自行安装一遍,拖了这么长时间,到今天才弄得差不多了。本来觉得这个不打算写个东西的,后来怕忘了,还是写下来吧
设备介绍
主机: ThinkStation-P300
CPU: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
GPU: Tesla K20c
所需软件
以下软件,在国内只有tensorflow需要翻墙,NVIDIA的都可以直接下载,速度还可以的
Ubuntu
Ubuntu
16.04.2 LTS
file_torrent
驱动
cuda
cuDNN
安装步骤
系统安装
安装Ubuntu的过程自行搜索吧,教程很多,在此不说了。 ### 选择正确的源
安装NVIDIA Driver
起初,我是选择使用直接安装cuda的,cuda中有driver,但是,cuda安装完了之后,重复出现登录界面,无法进入系统,所以,我选择单独安装driver,然后,再安装cuda。解决重复登录界面参考参考1
1.选择机子所需要的驱动,并下载。
2.卸载原有驱动:
1 | $ sudo apt-get remove –purge nvidia* |
3.关闭nouveau
创建 /etc/modprobe.d/blacklist-nouveau.conf并包含
1 | blacklist nouveau |
在terminal输入
sudo update-initramfs -u
4.进入命令行模式
Ctrl+Alt+F1
5.关闭lightdm服务
sudo service lightdm stop
6.运行驱动文件 改变权限
sudo chmod a+x NVIDIA-Linux-x86_64-375.39.run
运行 注意参数
sudo ./NVIDIA-Linux-x86_64-375.39.run –no-x-check –no-nouveau-check –no-opengl-files
- no-x-check 安装驱动时关闭X服务
- no-nouveau-check 安装驱动时禁用nouveau
- no-opengl-files 只安装驱动文件,不安装OpenGL文件7.重启,不出现循环登录问题,如果出现循环登陆, 请看后面的问题。
安装cuda
本来是按照deb安装的,后来各种问题,就改成选择runfile的方式了。
这里主要参考参考2,全是英文的,要是不想看英文的话,我觉得,那还是放弃做dnn吧,目前这个前沿领域中文文献比较少~
1.在运行.run文件之后,在选择是否安装驱动的位置选择no,剩下的都是yes。
2.添加环境变量
打开 ~/.bashrc在最后添加
1 | export PATH=/usr/local/cuda/bin:$PATH |
在terminal输入
source ~/.bashrc 3.测试cuda安装是否成功
nvcc -V 输入cuda的版本信息
4.测试samples
这部分参考参考3
进入 NVIDIA_CUDA-8.0-Samples/ make
运行NVIDIA_CUDA-8.0-Samples/bin/x86_64/linux/release/deviceQuery
显示最后出现“Resalt=PASS”,代表成功
安装cuDNN
安装之前一定要确认你的GPU是支持cuDNN的。 这个都不应该叫做安装,就是一个创建链接的过程。这个主要参考参考4
1.下载tar文件,解压
解压出一个叫做cuda的文件夹,以下操作都是在该文件夹下进行
2.复制文件
1 | sudo cp include/cuDNN.h /usr/local/include |
3.创建cuDNN的软链接
1 | $ sudo ln -sf /usr/local/lib/libcuDNN.so.5.1.10 /usr/local/lib/libcuDNN.so.5 |
Caffe install Prepare Dependencies
Install OpenCV from Source
自行进行官网查询或者采用如下脚本进行安装。 Install
OpenCV scripts
当然cmake可以采用最基本的:cmake ..进行就完全ok
安装结束之后,请务必添加OpenCV lib所在的路径添加到`LD_LIBRARY_PATH`,因为OpenCV 默认安装路径`/usr/local/lib`并不在`LD_LIBRARY_PATH`中。1 | export PATH=/usr/local/cuda/bin:$PATH |
Install Python dependencies
1 | sudo apt-get install -y python-pip |
等待python依赖的库安装完毕。 ok, 现在应该就可以运行example/下的某些例子了。
FAQ总结
hdf5.h没有找到
1 | CXX src/caffe/layer_factory.cpp |
方案一:
1 | cd /usr/lib/x86_64-linux-gnu |
方案二
just modify the Makefile.config INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial/ LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serial/ issues 2690
编译OpenCV syntax error: identifier 'NppiGraphcutState'
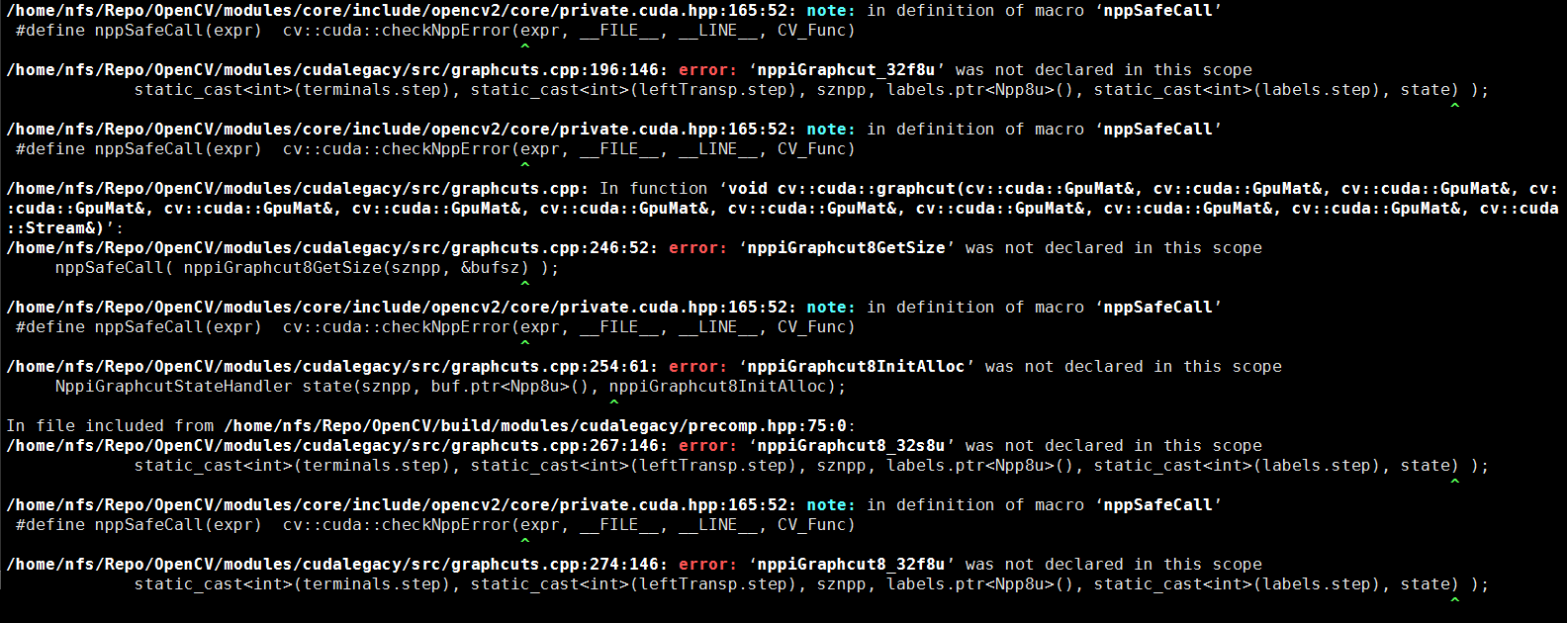
1 | 1>------ Build started: Project: opencv_cudalegacy, Configuration: Debug x64 ------ |
cudalegacy-not-compile-nppigraphcut-missing 这个问题在opencv中已经fix掉了。
将opencv.cpp中的
1 | #include "precomp.hpp" |
修改为:
1 | #include "precomp.hpp" |
ld链接失败,或者.o没有生成
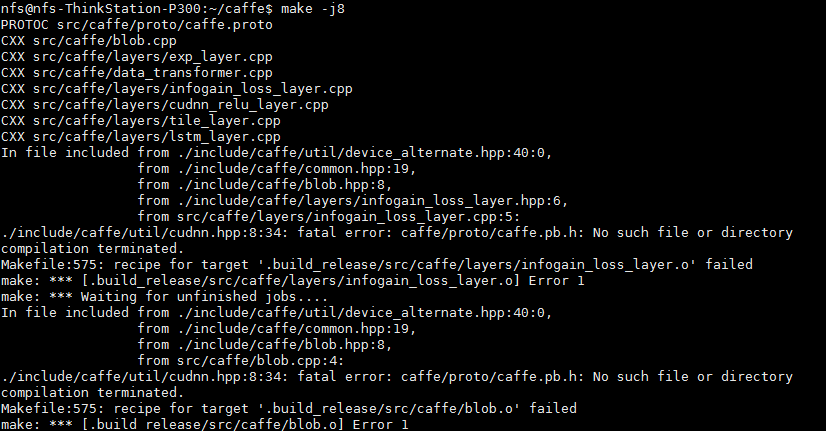 如果你使用的是
如果你使用的是make -j8进行编译的,并且你需要的lib已经都加到LD_LIBRARY_PATH中了,那么你可以再试一遍make -j8或者使用make -j4
or
make -j,最保险的情况就是使用make进行编译,虽然慢点但是不会出现各种依赖找不到的情况。
因为使用多线程编译的时候,不同线程编译不同的cpp文件,尤其是caffe编译过程中首先是要调用 `protoc` 进行生成 `caffe.pb.h` 的,如果多线程编译过程中,一个线程编译的cpp依赖caffe.pb.h,但是此时还没有生成完毕caffe.pb.h,就会出现类似错误。Opencv库找不到问题
1 | CXX/LD -o .build_release/tools/extract_features.bin |
在Makefile中LIBRARES中添加 opencv_imgcodecs项
循环登陆界面
方案一
- 卸掉nvidia-driver
sudo apt-get remove --purge nvidia* - 看看能不能登陆guest,可以的话 删除home/user/目录下的
.Xauthority .xsession-errors - reboot
方案二
卸掉nvidia-driver
sudo apt-get remove --purge nvidia*进入grub启动界面,可是使用advance 启动方式,进行修复界面。通过选择
recovery mode进行恢复之后,然后重启。后来经过调研和重新格式化系统进行安装之后发现,原来是CUDA7.5 的
.deb对Ubuntu 14.04 的支持性不好,导致显示驱动程序有问题,从而无法正常进入系统。而且有人建议采用.run的toolkit进行安装, 所以后面使用.run进行安装
双电源供电的一些坑
没有sudu权限,安装caffe
- 下载caffe 依赖包,解压到某个路径下。如果失活了, emailto:caowenlong92@gmail.com
- 添加caffelib/lib的绝对路径到~/.bashrc 中
export LD_LIBRARY_PATH=/home/.../caffelib/lib$LD_LIBRARY_PATH - 在Makefile.config中
INCLUDE_DIRS中添加caffelib/include的绝对路径;LIBRARY_DIRS中添加添加caffelib/lib的绝对路径 - cuda啥的一般管理员就帮你搞定了,实在不行咱自己安装到某个路径下,在Makefile.config中配置一下路径就ok了
- python 依赖可以通过
virtualenv解决掉的,如何使用virtualenv可以看官网
Quarto Fx580
查看显卡型号lspci | grep "VGA"
01:00.0 VGA compatible controller: NVIDIA Corporation G96GL [Quadro FX 580] (rev a1)查看GPU卡是否支持cuda 哦哦,并不支持,好吧,换卡吧。
error: ‘kEmptyString’ is not a member of ‘google::protobuf::internal’
这个比较玄,有的人使用protobuf
2.5就OK,有的人使用这个版本就爆出这个错误。我是使用libprotoc
2.5.0版本,当
使用make进行编译的时候就会出现该问题。当时如果采用make -j
https://blog.csdn.net/ahbbshenfeng/article/details/52065676
参考文献
1.【解决】Ubuntu安装NVIDIA驱动后桌面循环登录问题
2.NVIDIA
CUDA Installation Guide for Linux
4.import
TensorFlow提示Unable to load cuDNN DSO
5.Installing
TensorFlow on Ubuntu
10.IBM的google protocol buffer的介绍链接
11.protobuf-on-ubuntu-not-compiling
12.googleprotobufinternalkemptystring
Docker安装caffe
The standalone subfolder contains docker files for
generating both CPU and GPU executable images for Caffe. The images can
be built using make, or by running:
docker build -t caffe:cpu standalone/cpu for example. (Here
gpu can be substituted for cpu, but to keep
the readme simple, only the cpu case will be discussed in
detail).
Note that the GPU standalone requires a CUDA 8.0 capable driver to be
installed on the system and [nvidia-docker] for running the Docker
containers. Here it is generally sufficient to use
nvidia-docker instead of docker in any of the
commands mentioned.
1 | # 基础镜像 |
在docker镜像中运行caffe
In order to test the Caffe image, run:
docker run -ti caffe:cpu caffe --version
which should show a message like:
1 | libdc1394 error: Failed to initialize libdc1394 |
One can also build and run the Caffe tests in the image using:
docker run -ti caffe:cpu bash -c "cd /opt/caffe/build; make runtest"
In order to get the most out of the caffe image, some more advanced
docker run options could be used. For example, running:
docker run -ti --volume=$(pwd):/workspace caffe:cpu caffe train --solver=example_solver.prototxt
will train a network defined in the
example_solver.prototxt file in the current directory
($(pwd) is maped to the container volume
/workspace using the --volume= Docker
flag).
Note that docker runs all commands as root by default, and thus any output files (e.g. snapshots) generated will be owned by the root user. In order to ensure that the current user is used instead, the following command can be used:
docker run -ti --volume=$(pwd):/workspace -u $(id -u):$(id -g) caffe:cpu caffe train --solver=example_solver.prototxt
where the -u Docker command line option runs the
commands in the container as the specified user, and the shell command
id is used to determine the user and group ID of the
current user. Note that the Caffe docker images have
/workspace defined as the default working directory. This
can be overridden using the --workdir= Docker command line
option.
其他案例
Although running the caffe command in the docker
containers as described above serves many purposes, the container can
also be used for more interactive use cases. For example, specifying
bash as the command instead of caffe yields a
shell that can be used for interactive tasks. (Since the caffe build
requirements are included in the container, this can also be used to
build and run local versions of caffe).
Another use case is to run python scripts that depend on
caffe's Python modules. Using the python
command instead of bash or caffe will allow
this, and an interactive interpreter can be started by running:
docker run -ti caffe:cpu python
(ipython is also available in the container).
Since the caffe/python folder is also added to the path,
the utility executable scripts defined there can also be used as
executables. This includes draw_net.py,
classify.py, and detect.py
挂载本地目录到容器中
1 | cd cafferoot |
解析:--volume=$(pwd):/workspace是挂载本机目录到容器中,--volume or -v是docker的挂载命令,=$(pwd):/workspace是挂载信息,是将$(pwd)即本机当前目录,:是挂载到哪,/workspace是容器中的目录,就是把容器中的workspace目录换成本机的当前目录,这样就可以在本机与容器之间进行交互了,本机当前目录可以编辑,容器中同时能看到。容器中的workspace目录的修改也直接反应到了本机上。$()是Linux中的命令替换,即将\(()中的命令内容替换为参数,pwd是Linux查看当前目录,我的本机当前目录为cafferoot,`--volume=\)(pwd):/workspace就等于--volume=/Users//cafferoot:/workspace,/Users//cafferoot为pwd`的执行结果,$()是将pwd的执行结果作为参数执行。
一些有用的命令
基于image
nvidia/cuda运行某条命令nvidia-sminvidia-docker run nvidia/cuda nvidia-smi查看当前有哪些镜像
sudo nvidia-docker images查看当前有哪些运行中的实例
sudo nvidia-docker ps -l运行某个镜像的实例
sudo nvidia-docker run -it nvidia/cuda链接运行中的镜像
sudo nvidia-docker attach d641ab33bec2跳出运行中的image镜像,但是不退出
ctrl+p,ctrl+q使用linux命令对镜像实例进行操作
sudo nvidia-docker cp zeyu/VOCtrainval_11-May-2012.tar e6a0961ab4cf:/workspace/datasudo nvidia-docker run -it -t nvidia/cuda nvidia-smi在host机器上启动新的bash
sudo nvidia-docker exec -it d641ab33bec2 bash
TLS handshake timeout 问题
iscas@ZXC-Lenovo:~/Repo$ sudo docker build -t caffe:cpu docker/caffe Sending build context to Docker daemon 3.072 kB Step 1/12 : FROM ubuntu:14.04 Get https://registry-1.docker.io/v2/: net/http: TLS handshake timeout
很明显可以看出是连接不到 docker hub,那就需要查看网络原因了。当然较简单的解决办法就是用国内的仓库, 下面的方法就是使用国内的 daocloud 的仓库:
添加国内库的依赖
$ echo "DOCKER_OPTS="$DOCKER_OPTS --registry-mirror=http://f2d6cb40.m.daocloud.io"" | sudo tee -a /etc/default/docker
重启服务
$ sudo service docker restart
更多问题可以查看[3]
Docker相关的参考文献
[docker install caffe]https://github.com/cwlseu/caffe/edit/master/docker/README.md
[Pull Docker image的时候遇到docker pull TLS handshake timeout]https://blog.csdn.net/han_cui/article/details/55190319
[caffe cpu docker]https://hub.docker.com/r/elezar/caffe/