Inference Framework based TensorRT
引言
视觉算法经过几年高速发展,大量的算法被提出。为了能真正将算法在实际应用场景中更好地应用,高性能的 inference框架层出不穷。从手机端上的ncnn到tf-lite,NVIDIA在cudnn之后,推出专用于神经网络推理的TensorRT. 经过几轮迭代,支持的操作逐渐丰富,补充的插件已经基本满足落地的需求。笔者觉得,尤其是tensorrt 5.0之后,无论是接口还是使用samples都变得非常方便集成。
NVIDIA® TensorRT™ 是一款用于高性能深度学习推理的
SDK,包括深度学习推理优化器和Runtime,可为推理应用程序提供低延迟和高吞吐量。TensorRT项目立项的时候名字叫做GPU
Inference
Engine(简称GIE),Tensor表示数据流动以张量的形式。所谓张量大家可以理解为更加复杂的高维数组,一般一维数组叫做Vector(即向量),二维数组叫做Matrix,再高纬度的就叫Tensor,Matrix其实是二维的Tensor。在TensoRT中,所有的数据都被组成最高四维的数组,如果对应到CNN中其实就是{N, C, H, W},N表示batch
size,即多少张图片或者多少个推断(Inference)的实例;C表示channel数目;H和W表示图像或feature
maps的高度和宽度。RT表示的是Runtime.
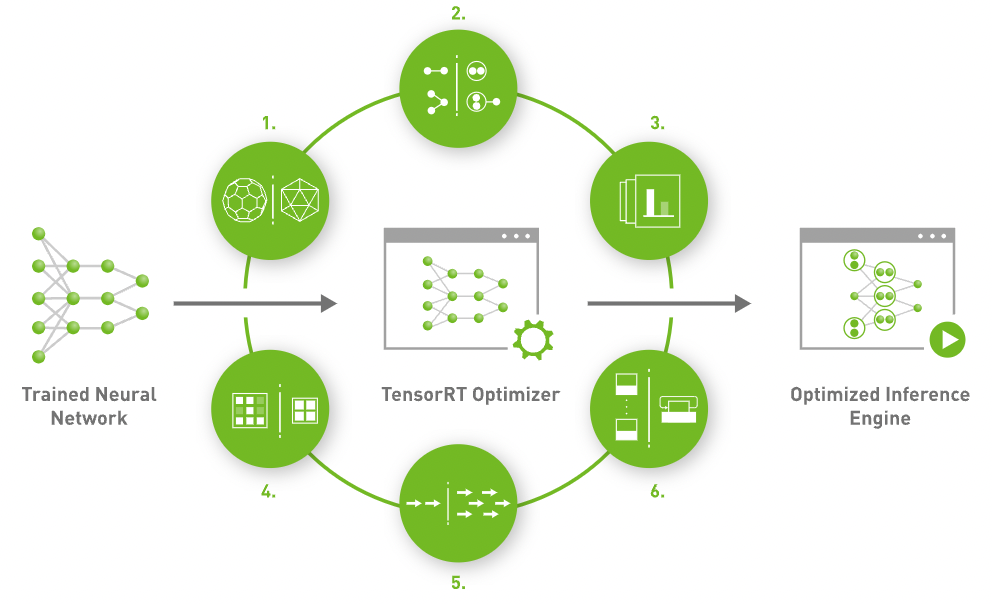
版本选型与基本概念
FP16 INT8
The easiest way to benefit from mixed precision in your application is to take advantage of the support for FP16 and INT8 computation in NVIDIA GPU libraries. Key libraries from the NVIDIA SDK now support a variety of precisions for both computation and storage.
Table shows the current support for FP16 and INT8 in key CUDA libraries as well as in PTX assembly and CUDA C/C++ intrinsics.
| Feature | FP16x2 | INT8/16 DP4A/DP2A |
|---|---|---|
| PTX instructions | CUDA 7.5 | CUDA 8 |
| CUDA C/C++ intrinsics | CUDA 7.5 | CUDA 8 |
| cuBLAS GEMM | CUDA 7.5 | CUDA 8 |
| cuFFT | CUDA 7.5 | I/O via cuFFT callbacks |
| cuDNN | 5.1 | 6 |
| TensorRT | v1 | v2 Tech Preview |
PTX
PTX(parallel-thread-execution,并行线程执行) 预编译后GPU代码的一种形式,开发者可以通过编译选项 “-keep”选择输出PTX代码,当然开发人员也可以直接编写PTX级代码。另外,PTX是独立于GPU架构的,因此可以重用相同的代码适用于不同的GPU架构。 具体可参考CUDA-PDF之《PTX ISA reference document》
建议我们的CUDA 版本为CUDA 8.0以上,
显卡至少为GeForce 1060,
如果想支持Int8/DP4A等feature,还是需要RTX 1080或者P40。
TensorRT特性助力高性能算法
优化技术包括:
- Weight & Activation Precision Calibration: 在保持精度的情况下能够量化模型到INT8,最大化吞吐
- Layer & Tensor Fusion: 通过融合多个Op到一个kernel,优化GPU显存和IO
- Kernel Auto-Tuning: 基于目标GPU特点,选择最佳GEMM计算方式,优化Op的计算性能
- Dynamic Tensor Memory: 最大限度地减少内存占用并有效地为张量重用内存
- Multi-Stream Execution: 可扩展设计以并行处理多个输入流
- Time Fusion: 使用动态生成的Kernel优化循环神经网络
优化原理

网络模型的裁剪与重构
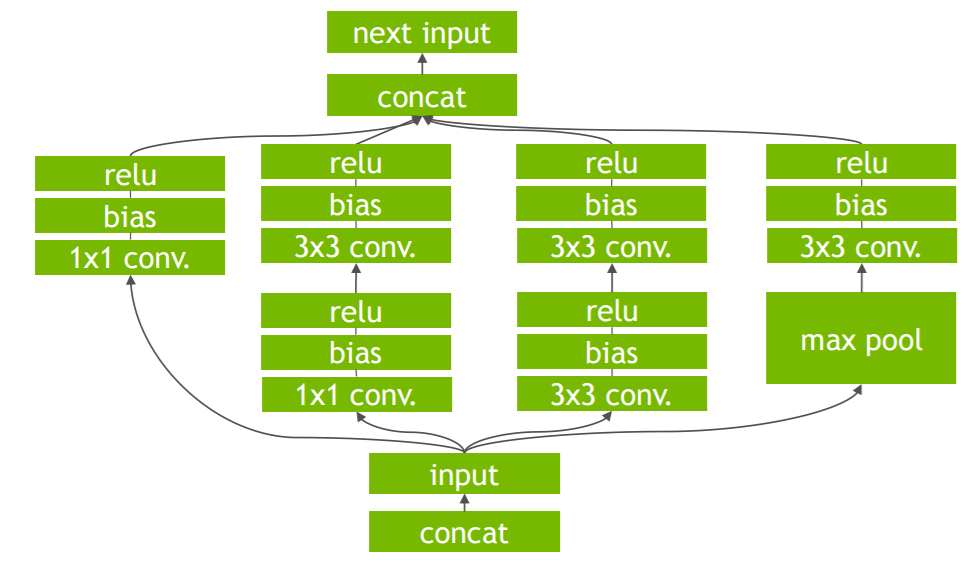
The above figures explain the vertical fusion optimization that TRT
does. The Convolution (C), Bias(B) and
Activation(R, ReLU in this case) are all collapsed into one
single node (implementation wise this would mean a single CUDA kernel
launch for C, B and R).
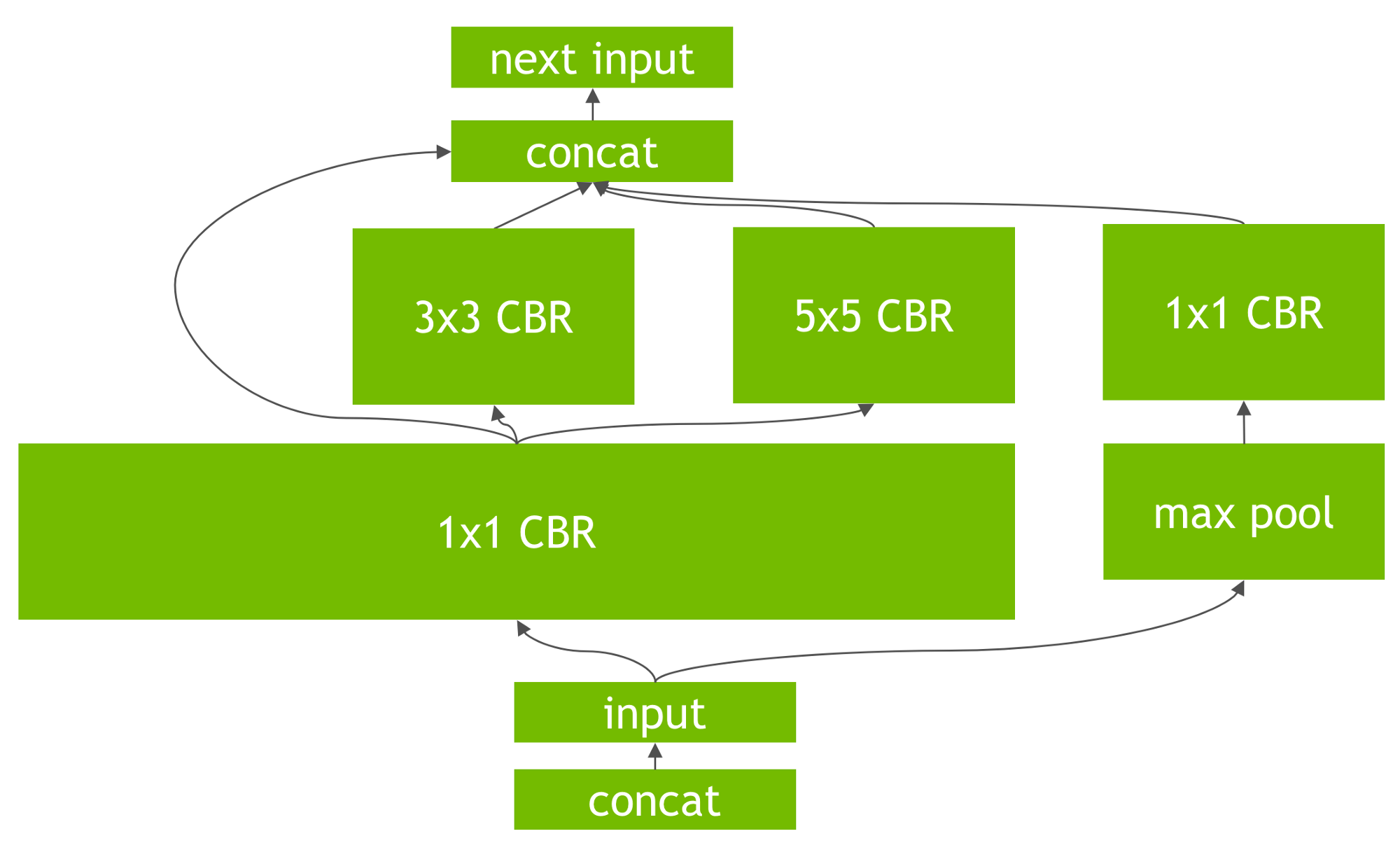
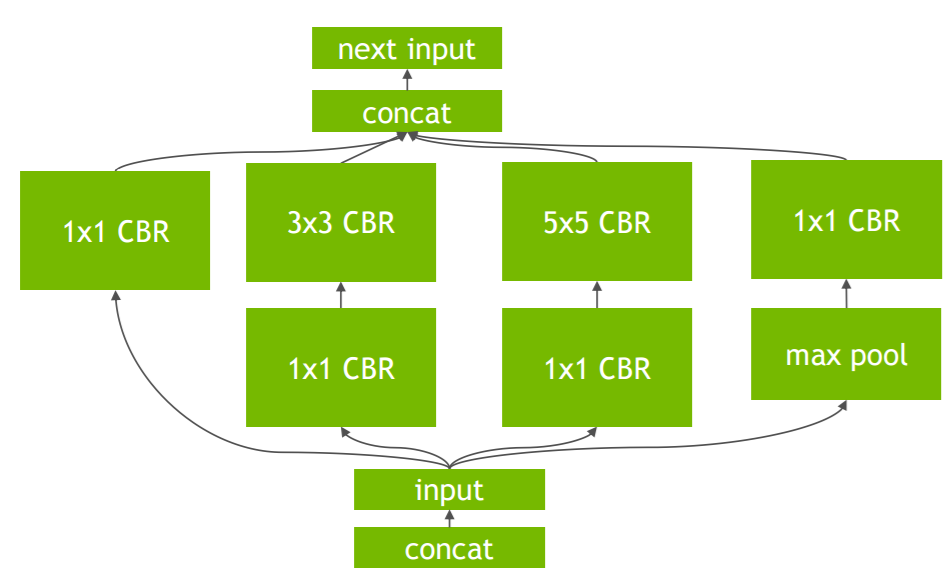
There is also a horizontal fusion where if multiple nodes with same operation are feeding to multiple nodes then it is converted to one single node feeding multiple nodes. The three 1x1 CBRs are fused to one and their output is directed to appropriate nodes. Other optimizations Apart from the graph optimizations, TRT, through experiments and based on parameters like batch size, convolution kernel(filter) sizes, chooses efficient algorithms and kernels(CUDA kernels) for operations in network.
低精度计算的支持
- FP16 & Int8指令的支持
- DP4A(Dot Product of 4 8-bits Accumulated to a 32-bit)
TensorRT 进行优化的方式是 DP4A (Dot Product of 4 8-bits Accumulated to a 32-bit),如下图:
 这是PASCAL
系列GPU的硬件指令,INT8卷积就是使用这种方式进行的卷积计算。更多关于DP4A的信息可以参考Mixed-Precision
Programming with CUDA 8
这是PASCAL
系列GPU的硬件指令,INT8卷积就是使用这种方式进行的卷积计算。更多关于DP4A的信息可以参考Mixed-Precision
Programming with CUDA 8
INT8 vector dot products (DP4A) improve the efficiency of radio astronomy cross-correlation by a large factor compared to FP32 computation.
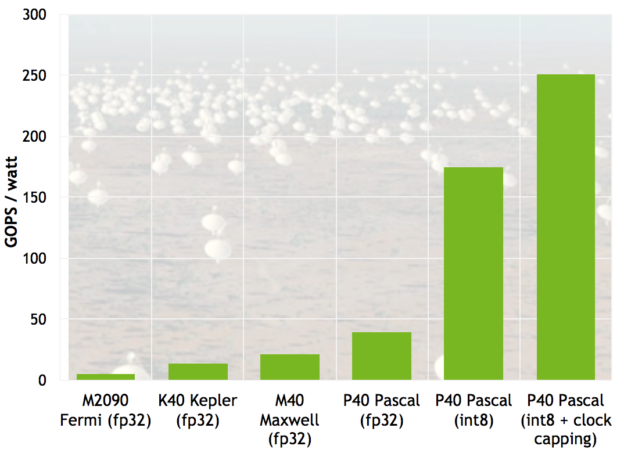
硬件方面Tensor Core的支持,优化卷积运算
这个需要硬件的支持,如果没有类似Volta架构的GPU就不要强求。
Framework TODO SCHEDULE
- model load sample
模型初始化当前包括通过parser初始化和通过模型流初始化的方式。通过parser初始化过程相比较来说比较慢,因为包含parser过程
- caffe model
- gie model
- plugin & extend layers
- 设计plugin的管理机制,更新初始化流程
- interp
- ROIPooling
- RPNProposal
- PriorBox
- ChannelShuffle
- CTC
- SLLSTM
- int8 quantity inference
- 矫正算法的设计
- 量化数据集合的管理,这个可以和NNIE的量化数据统一起来管理
- 与研究侧共同确定各个层量化的范围
- 最后更新inference模式
2022年更新
随着TensorRT的更新,当前已经支持到8.5版本,对Transformer类的支持已经获得了长足发展,尤其是对Onnx Parser的成熟与完善,使得我们在实际项目应用中能够用更少的成本来获得较大的推理性能收益。
Supported ONNX Operators
TensorRT 8.5 supports operators up to Opset 17. Latest information of ONNX operators can be found here
TensorRT supports the following ONNX data types: DOUBLE, FLOAT32, FLOAT16, INT8, and BOOL
Note: There is limited support for INT32, INT64, and DOUBLE types. TensorRT will attempt to cast down INT64 to INT32 and DOUBLE down to FLOAT, clamping values to
+-INT_MAXor+-FLT_MAXif necessary.
See below for the support matrix of ONNX operators in ONNX-TensorRT.
| Operator | Supported | Supported Types | Restrictions | Description |
|---|---|---|---|---|
| Abs | Y | FP32, FP16, INT32 | ||
| Acos | Y | FP32, FP16 | ||
| Acosh | Y | FP32, FP16 | ||
| Add | Y | FP32, FP16, INT32 | ||
| And | Y | BOOL | ||
| ArgMax | Y | FP32, FP16 | ||
| ArgMin | Y | FP32, FP16 | ||
| Asin | Y | FP32, FP16 | ||
| Asinh | Y | FP32, FP16 | ||
| Atan | Y | FP32, FP16 | ||
| Atanh | Y | FP32, FP16 | ||
| AveragePool | Y | FP32, FP16, INT8, INT32 | 2D or 3D Pooling only | |
| BatchNormalization | Y | FP32, FP16 | ||
| Bernoulli | N | |||
| BitShift | N | |||
| BlackmanWindow | N | |||
| Cast | Y | FP32, FP16, INT32, INT8, BOOL | ||
| Ceil | Y | FP32, FP16 | ||
| Celu | Y | FP32, FP16 | ||
| Clip | Y | FP32, FP16, INT8 | ||
| Compress | N | |||
| Concat | Y | FP32, FP16, INT32, INT8, BOOL | ||
| ConcatFromSequence | N | |||
| Constant | Y | FP32, FP16, INT32, INT8, BOOL | ||
| ConstantOfShape | Y | FP32 | ||
| Conv | Y | FP32, FP16, INT8 | ||
| ConvInteger | N | |||
| ConvTranspose | Y | FP32, FP16, INT8 | ||
| Cos | Y | FP32, FP16 | ||
| Cosh | Y | FP32, FP16 | ||
| CumSum | Y | FP32, FP16 | axis must be an initializer |
|
| DFT | N | |||
| DepthToSpace | Y | FP32, FP16, INT32 | ||
| DequantizeLinear | Y | INT8 | x_zero_point must be zero |
|
| Det | N | |||
| Div | Y | FP32, FP16, INT32 | ||
| Dropout | Y | FP32, FP16 | ||
| DynamicQuantizeLinear | N | |||
| Einsum | Y | FP32, FP16 | Ellipsis and diagonal operations are not supported. Broadcasting between inputs is not supported | |
| Elu | Y | FP32, FP16, INT8 | ||
| Equal | Y | FP32, FP16, INT32 | ||
| Erf | Y | FP32, FP16 | ||
| Exp | Y | FP32, FP16 | ||
| Expand | Y | FP32, FP16, INT32, BOOL | ||
| EyeLike | Y | FP32, FP16, INT32, BOOL | ||
| Flatten | Y | FP32, FP16, INT32, BOOL | ||
| Floor | Y | FP32, FP16 | ||
| Gather | Y | FP32, FP16, INT8, INT32, BOOL | ||
| GatherElements | Y | FP32, FP16, INT8, INT32, BOOL | ||
| GatherND | Y | FP32, FP16, INT8, INT32, BOOL | ||
| Gemm | Y | FP32, FP16, INT8 | ||
| GlobalAveragePool | Y | FP32, FP16, INT8 | 使用输入张量\(X\)
并对同一通道中的值应用平均池化。
这相当于内核大小等于输入张量的空间维度的 AveragePool。 |
|
| GlobalLpPool | Y | FP32, FP16, INT8 | ||
| GlobalMaxPool | Y | FP32, FP16, INT8 | ||
| Greater | Y | FP32, FP16, INT32 | ||
| GreaterOrEqual | Y | FP32, FP16, INT32 | ||
| GridSample | Y | FP32, FP16 | ||
| GRU | Y | FP32, FP16 | For bidirectional GRUs, activation functions must be the same for both the forward and reverse pass | |
| HammingWindow | N | |||
| HannWindow | N | |||
| HardSwish | Y | FP32, FP16, INT8 | ||
| HardSigmoid | Y | FP32, FP16, INT8 | ||
| Hardmax | N | |||
| Identity | Y | FP32, FP16, INT32, INT8, BOOL | ||
| If | Y | FP32, FP16, INT32, BOOL | Output tensors of the two conditional branches must have broadcastable shapes, and must have different names | |
| ImageScaler | Y | FP32, FP16 | ||
| InstanceNormalization | Y | FP32, FP16 | Scales scale and biases B must be
initializers. Input rank must be >=3 & <=5 |
|
| IsInf | N | |||
| IsNaN | Y | FP32, FP16, INT32 | ||
| LayerNormalization | N | |||
| LeakyRelu | Y | FP32, FP16, INT8 | ||
| Less | Y | FP32, FP16, INT32 | ||
| LessOrEqual | Y | FP32, FP16, INT32 | ||
| Log | Y | FP32, FP16 | ||
| LogSoftmax | Y | FP32, FP16 | ||
| Loop | Y | FP32, FP16, INT32, BOOL | ||
| LRN | Y | FP32, FP16 | ||
| LSTM | Y | FP32, FP16 | For bidirectional LSTMs, activation functions must be the same for both the forward and reverse pass | |
| LpNormalization | Y | FP32, FP16 | ||
| LpPool | Y | FP32, FP16, INT8 | ||
| MatMul | Y | FP32, FP16 | ||
| MatMulInteger | N | |||
| Max | Y | FP32, FP16, INT32 | ||
| MaxPool | Y | FP32, FP16, INT8 | 2D or 3D pooling only. Indices output tensor
unsupported |
|
| MaxRoiPool | N | |||
| MaxUnpool | N | |||
| Mean | Y | FP32, FP16, INT32 | ||
| MeanVarianceNormalization | Y | FP32, FP16 | ||
| MelWeightMatrix | N | |||
| Min | Y | FP32, FP16, INT32 | ||
| Mod | Y | FP32, FP16, INT32 | ||
| Mul | Y | FP32, FP16, INT32 | ||
| Multinomial | N | |||
| Neg | Y | FP32, FP16, INT32 | ||
| NegativeLogLikelihoodLoss | N | |||
| NonMaxSuppression | Y | FP32, FP16 | ||
| NonZero | Y | FP32, FP16 | ||
| Not | Y | BOOL | ||
| OneHot | Y | FP32, FP16, INT32, BOOL | ||
| Optional | N | |||
| OptionalGetElement | N | |||
| OptionalHasElement | N | |||
| Or | Y | BOOL | ||
| Pad | Y | FP32, FP16, INT8, INT32 | ||
| ParametricSoftplus | Y | FP32, FP16, INT8 | ||
| Pow | Y | FP32, FP16 | ||
| PRelu | Y | FP32, FP16, INT8 | ||
| QLinearConv | N | |||
| QLinearMatMul | N | |||
| QuantizeLinear | Y | FP32, FP16 | y_zero_point must be 0 |
|
| RandomNormal | Y | FP32, FP16 | seed value is ignored by TensorRT |
|
| RandomNormalLike | Y | FP32, FP16 | seed value is ignored by TensorRT |
|
| RandomUniform | Y | FP32, FP16 | seed value is ignored by TensorRT |
|
| RandomUniformLike | Y | FP32, FP16 | seed value is ignored by TensorRT |
|
| Range | Y | FP32, FP16, INT32 | ||
| Reciprocal | Y | FP32, FP16 | ||
| ReduceL1 | Y | FP32, FP16 | ||
| ReduceL2 | Y | FP32, FP16 | ||
| ReduceLogSum | Y | FP32, FP16 | ||
| ReduceLogSumExp | Y | FP32, FP16 | ||
| ReduceMax | Y | FP32, FP16 | ||
| ReduceMean | Y | FP32, FP16 | ||
| ReduceMin | Y | FP32, FP16 | ||
| ReduceProd | Y | FP32, FP16 | ||
| ReduceSum | Y | FP32, FP16 | ||
| ReduceSumSquare | Y | FP32, FP16 | ||
| Relu | Y | FP32, FP16, INT8 | ||
| Reshape | Y | FP32, FP16, INT32, INT8, BOOL | ||
| Resize | Y | FP32, FP16 | Supported resize transformation modes: half_pixel,
pytorch_half_pixel, tf_half_pixel_for_nn,
asymmetric, and align_corners.Supported resize modes: nearest, linear.Supported nearest modes: floor, ceil,
round_prefer_floor, round_prefer_ceil |
|
| ReverseSequence | Y | FP32, FP16 | Dynamic input shapes are unsupported | |
| RNN | Y | FP32, FP16 | For bidirectional RNNs, activation functions must be the same for both the forward and reverse pass | |
| RoiAlign | Y | FP32, FP16 | ||
| Round | Y | FP32, FP16, INT8 | ||
| STFT | N | |||
| ScaledTanh | Y | FP32, FP16, INT8 | ||
| Scan | Y | FP32, FP16 | ||
| Scatter | Y | FP32, FP16, INT8, INT32 | ||
| ScatterElements | Y | FP32, FP16, INT8, INT32 | ||
| ScatterND | Y | FP32, FP16, INT8, INT32 | ||
| Selu | Y | FP32, FP16, INT8 | ||
| SequenceAt | N | |||
| SequenceConstruct | N | |||
| SequenceEmpty | N | |||
| SequenceErase | N | |||
| SequenceInsert | N | |||
| SequenceLength | N | |||
| SequenceMap | N | |||
| Shape | Y | FP32, FP16, INT32, INT8, BOOL | ||
| Shrink | Y | FP32, FP16, INT32 | ||
| Sigmoid | Y | FP32, FP16, INT8 | ||
| Sign | Y | FP32, FP16, INT8, INT32 | ||
| Sin | Y | FP32, FP16 | ||
| Sinh | Y | FP32, FP16 | ||
| Size | Y | FP32, FP16, INT32, INT8, BOOL | ||
| Slice | Y | FP32, FP16, INT32, INT8, BOOL | axes must be an initializer |
|
| Softmax | Y | FP32, FP16 | ||
| SoftmaxCrossEntropyLoss | N | |||
| Softplus | Y | FP32, FP16, INT8 | ||
| Softsign | Y | FP32, FP16, INT8 | ||
| SpaceToDepth | Y | FP32, FP16, INT32 | ||
| Split | Y | FP32, FP16, INT32, BOOL | ||
| SplitToSequence | N | |||
| Sqrt | Y | FP32, FP16 | ||
| Squeeze | Y | FP32, FP16, INT32, INT8, BOOL | axes must be an initializer |
|
| StringNormalizer | N | |||
| Sub | Y | FP32, FP16, INT32 | ||
| Sum | Y | FP32, FP16, INT32 | ||
| Tan | Y | FP32, FP16 | ||
| Tanh | Y | FP32, FP16, INT8 | ||
| TfIdfVectorizer | N | |||
| ThresholdedRelu | Y | FP32, FP16, INT8 | ||
| Tile | Y | FP32, FP16, INT32, BOOL | ||
| TopK | Y | FP32, FP16 | K input must be an initializer |
|
| Transpose | Y | FP32, FP16, INT32, INT8, BOOL | ||
| Trilu | Y | FP32, FP16, INT32, INT8, BOOL | ||
| Unique | N | |||
| Unsqueeze | Y | FP32, FP16, INT32, INT8, BOOL | axes must be a constant tensor |
|
| Upsample | Y | FP32, FP16 | ||
| Where | Y | FP32, FP16, INT32, BOOL | ||
| Xor | Y | BOOL |
Reference
- NVDLA官网
- NVIDIA blog: Production Deep Learning with NVIDIA GPU Inference Engine
- TensorRT 5.1的技术参数文档
- nvdla-sw-Runtime environment
- Szymon Migacz, NVIDIA: 8-bit Inference with TensorRT
- INT8量化校准原理
- Mixed-Precision Programming with CUDA 8
- Tensorflow使用TensorRT高速推理
- Tensorflow使用TensorRT高速推理视频
附录
Init.CaffeModel
1 | [I] Output "prob": 1000x1x1 |
Init.GIEModel
1 | [I] [TRT] Glob Size is 40869280 bytes. |
IPlugin接口中需要被重载的函数
确定输出:一个是通过
int getNbOutput()得到output输出的数目,即用户所定义的一层有几个输出。另一个是通过Dims getOutputDimensions (int index, const Dims* inputs, int nbInputDims)得到整个输出的维度信息,大家可能不一定遇到有多个输出,一般来讲只有一个输出,但是大家在做检测网络的时候可能会遇到多个输出,一个输出是实际的检测目标是什么,另一个输出是目标的数目,可能的过个输出需要设定Dimension的大小。层配置:通过
void configure()实现构建推断(Inference) engine时模型中相应的参数大小等配置,configure()只是在构建的时候调用,这个阶段确定的东西是在运行时作为插件参数来存储、序列化/反序列化的。资源管理:通过
void Initialize()来进行资源的初始化,void terminate()来销毁资源,甚至中间可能会有一些临时变量,也可以使用这两个函数进行初始化或销毁。需要注意的是,void Initialize()和void terminate()是在整个运行时都被调用的,并不是做完一次推断(Inference)就去调用terminate。相当于在线的一个服务,服务起的时候会调用void Initialize(),而服务止的时候调用void terminate(),但是服务会进进出出很多sample去做推断(Inference)。执行(Execution):
void enqueue()来定义用户层的操作序列化和反序列化:这个过程是将层的参数写入到二进制文件中,需要定义一些序列化的方法。通过
size_t getSerializationSize()获得序列大小,通过void serialize()将层的参数序列化到缓存中,通过PluginSample()从缓存中将层参数反序列化。需要注意的是,TensorRT没有单独的反序列化的API,因为不需要,在实习构造函数的时候就完成了反序列化的过程从Caffe Parser添加Plugin:首先通过
Parsernvinfer1::IPlugin* createPlugin()实现nvcaffeparser1::IPlugin 接口,然后传递工厂实例到ICaffeParser::parse(),Caffe的Parser才能识别运行时创建插件:通过
IPlugin* createPlugin()实现nvinfer1::IPlugin接口,传递工厂实例到IInferRuntime::deserializeCudaEngine()
TensorRT 中已经实现的Plugin
打开verbose logger之后可以看到如下输出,相关的调用接口如下:
1 | [V] [TRT] Plugin Creator registration succeeded - GridAnchor_TRT |
1 | extern "C" { |
https://medium.com/@r7vme/converting-neural-network-to-tensorrt-part-1-using-existing-plugins-edd9c2b9e42a