认识神经网络:卷积,归一化,优化和语料
引言
一个基于神经网络模型的视觉模型中,卷积和归一化层是最为耗时的两种layer。卷积数据计算密集类型,今年来大量的优化主要集中在各种设备上的卷积加速。 归一化层通过计算一个批量中的均值与方差来进行特征归一化。众多实践证明,它利于优化且使得深度网络易于收敛。批统计的随机不确定性也作为一个有利于泛化的正则化项。BN 已经成为了许多顶级计算机视觉算法的基础。添加归一化层作为提高算法性能的很好的一种策略,但由于像BN遭受数据同步延时的问题,现在逐渐被一些新的normalization方式所替代。
卷积
认识卷积
卷积定义
\[h(x) = f(x)*g(x) = \int_{ - \infty }^{ + \infty } {f(t)g(x - t)dt}\]
\(f(t)\)先不动, \(g(-t)\)相当于\(g(t)\)函数的图像沿y轴(t=0)做了一次翻转。\(g(x-t)\)相当于\(g(-t)\)的整个图像沿着t轴进行了平移,向右平移了x个单位。他们相乘之后围起来的面积就是\(h(x)\)。
离散卷积的定义
\[h(x) = f(x)*g(x) = \sum_{\tau = -\infty}^{+\infty}f(\tau)g(x-\tau)\]
其实,深度学习中的卷积对应于数学中的cross correlation. 从卷积的定义来看,我们当前在深度学习中训练的卷积核是翻转之后的卷积核。
下面是一些介绍卷积的文章和常见卷积类型统计表: * A Comprehensive Introduction to Different Types of Convolutions in Deep Learning * A Tutorial on Filter Groups (Grouped Convolution) * AlexNet * MobileNet * An Introduction to different Types of Convolutions in Deep Learning * Convolution arithmetic * Deconvolution and Checkerboard Artifacts
| Convolution Name | 参考文献 | 典型代表 | 附录 |
|---|---|---|---|
| Convolution | AlexNet, VGG | ||
| 1x1 | Network in Network | GoogLeNet, Inception | (1). Dimensionality reduction for
efficient computations; (2).Efficient low dimensional embedding, or feature pooling; (3). Applying nonlinearity again after convolution |
| Dilated convolution | Multi-Scale Context Aggregation by Dilated Convolutions | 语义分割 | support exponentially expanding receptive
fields without losing resolution or coverage.
Upsampling/poolinglayer(e.g. bilinear interpolation) is deterministic.
(a.k.a. not learnable); 内部数据结构丢失, 空间层级化信息丢失; 小物体信息无法重建 (假设有四个pooling layer则任何小于\(2^4=16\)pixel的物体信息将理论上无法重建。) 如何理解空洞卷积 |
| Group Convolution | Deep Roots:Improving CNN Efficiency with Hierarchical Filter Groups | MobileNet, ResNeXt | |
| Pointwise grouped convolution | ShuffleNet | ||
| Depthwise separable convolution | Xception: Deep Learning with Depthwise Separable Convolutions | Xception | MobileNet是典型的代表,通过该卷积,大大降低了计算复杂度和模型大小。也是现在落地产品中移动端常用的操作。 |
| Deconvolutions | Deconvolution and Checkerboard Artifacts | DSSD | Deconvolution也是一种常用的上采样方式,在物体分割和多尺度检测都可用到 |
| Flattened convolutions | Flattened convolutional neural networks for feedforward acceleration | computation costs due to the significant reduction of learning parameters. |
卷积的实现
计算卷积的方法有很多种,常见的有以下几种方法: * 滑窗:这种方法是最直观最简单的方法。但是,该方法不容易实现大规模加速,因此,通常情况下不采用这种方法 (但是也不是绝对不会用,在一些特定的条件下该方法反而是最高效的.) * im2col: 目前几乎所有的主流计算框架包括[Caffe]1, MXNet等都实现了该方法。该方法把整个卷积过程转化成了GEMM过程,而GEMM在各种BLAS库中都是被极致优化的,一般来说,速度较快. * FFT: 傅里叶变换和快速傅里叶变化是在经典图像处理里面经常使用的计算方法,但是,在 ConvNet 中通常不采用,主要是因为在 ConvNet 中的卷积模板通常都比较小,例如3×3 等,这种情况下,FFT 的时间开销反而更大. * [Winograd]2: Winograd 是存在已久最近被重新发现的方法,在大部分场景中,Winograd 方法都显示和较大的优势,目前cudnn中计算卷积就使用了该方法.
计算复杂度分析
- 假设输入\(I = R^{C_0H_0W_0}\), 卷积核大小为\(k\), 输出\(O = R^{C_1H_1W_1}\), 则卷积过程的计算量为:
\[(k^2C_0*H_1W_1)*C_1\]
使用Depthwise separable convolution卷积的计算量为:
\[(k^2*H_1W_1*C_0 + C_0C_1*H_1W_1)\]
那么计算量之比为
\[ \frac{(k^2*H_1W_1*C_0 + C_0C_1*H_1W_1)}{(k^2C_0*H_1W_1)*C_1} =\frac{1}{C_1} + \frac{1}{k^2} \approx \frac{1}{k^2} \]
一般情况下,\(k^2 << C_1\), 所以当\(k=3\)的时候,计算量之比约为原来的\(\frac{1}{9}\).
- 假设input的\(H_0 = W_0\),用\(w\)表示,\(k\)是卷积核的大小,\(p\)表示填充的大小,\(s\)表示stride步长
\[o = \frac{w - k + 2p}{s} + 1\]
Normalization
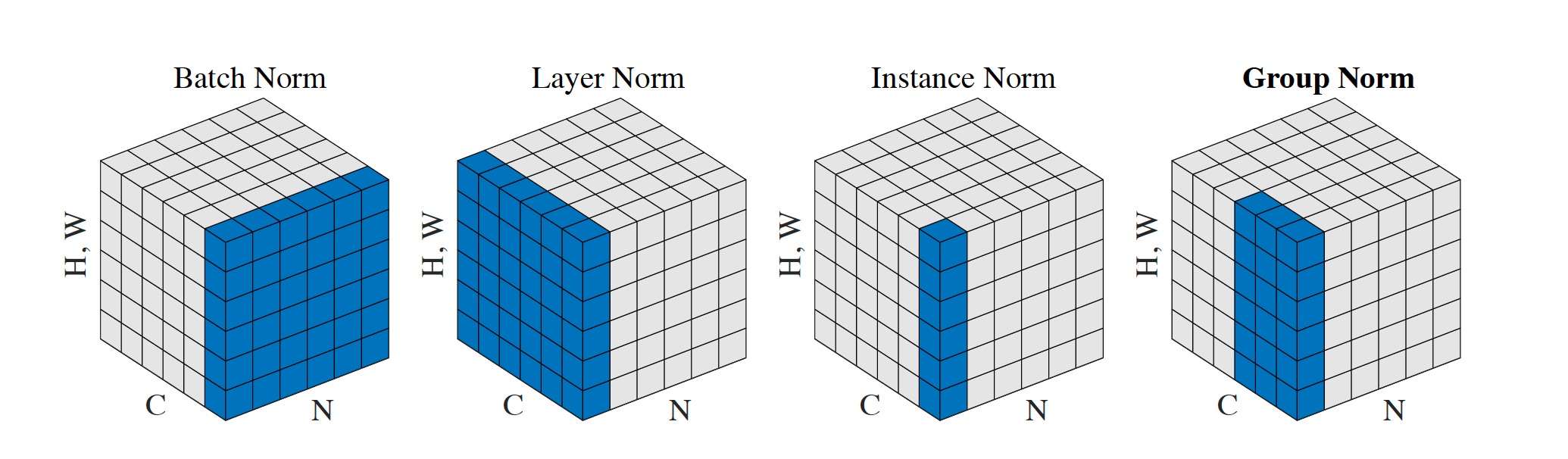 每个子图表示一个feature map张量,以\(N\)为批处理轴,\(C\)为通道轴,\((H,W)\)作为空间轴。其中蓝色区域内的像素使用相同的均值和方差进行归一化,并通过聚合计算获得这些像素的值。从示意图中可以看出,GN没有在N维度方向上进行拓展,因此batch
size之间是独立的,GPU并行化容易得多。
每个子图表示一个feature map张量,以\(N\)为批处理轴,\(C\)为通道轴,\((H,W)\)作为空间轴。其中蓝色区域内的像素使用相同的均值和方差进行归一化,并通过聚合计算获得这些像素的值。从示意图中可以看出,GN没有在N维度方向上进行拓展,因此batch
size之间是独立的,GPU并行化容易得多。
- batchNorm是在batch上,对NHW做归一化,对小batchsize效果不好;
- layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
- instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
- GroupNorm将channel分组,然后再做归一化;
- SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
Batch Normalization
需要比较大的Batch Size,需要更强的计算硬件的支持。
A small batch leads to inaccurate estimation of the batch statistics, and reducing BN’s batch size increases the model error dramatically
尤其是在某些需要高精度输入的任务中,BN有很大局限性。同时,BN的实现是在Batch size之间进行的,需要大量的数据交换。
batch normalization存在以下缺点:
- 对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
- BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。(参考于https://blog.csdn.net/lqfarmer/article/details/71439314)
Layer Normalizaiton
LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差; BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
Instance Normalization
BN注重对每个batch进行归一化,保证数据分布一致,因为判别模型中结果取决于数据整体分布。
但是图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
Group Normalization
GN does not exploit the batch dimension, and its computation is independent of batch sizes.
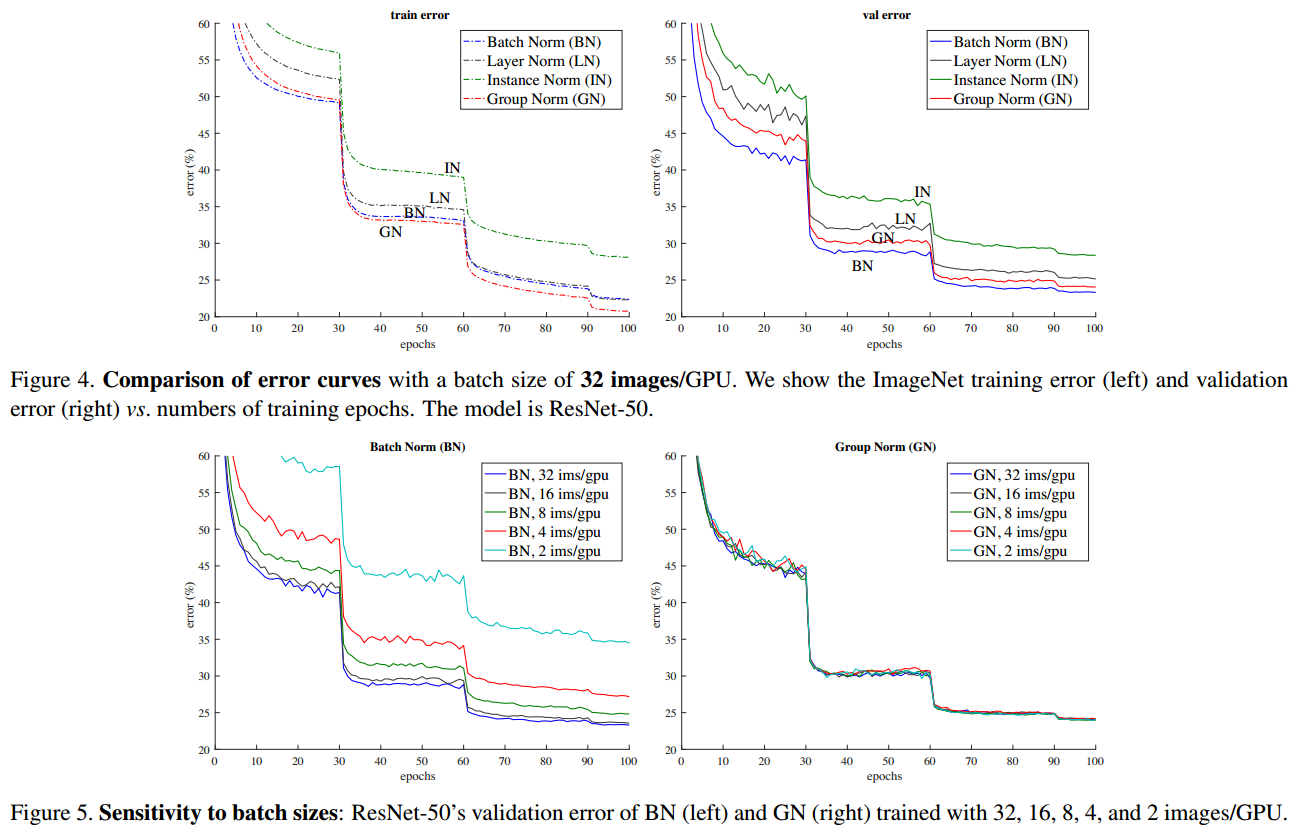 从实验结果中可以看出在训练集合上GN的valid
error低于BN,但是测试结果上逊色一些。这个
可能是因为BN的均值和方差计算的时候,通过随机批量抽样(stochastic
batch sampling)引入了不确定性因素,这有助于模型参数正则化。
而这种不确定性在GN方法中是缺失的,这个将来可能通过使用不同的正则化算法进行改进。
从实验结果中可以看出在训练集合上GN的valid
error低于BN,但是测试结果上逊色一些。这个
可能是因为BN的均值和方差计算的时候,通过随机批量抽样(stochastic
batch sampling)引入了不确定性因素,这有助于模型参数正则化。
而这种不确定性在GN方法中是缺失的,这个将来可能通过使用不同的正则化算法进行改进。
LRN(Local Response Normalization)
动机
在神经深武学有一个概念叫做侧抑制(lateral inhibitio),指的是被激活的神经元抑制相邻的神经元。 归一化的目的就是“抑制”,局部响应归一化就是借鉴侧抑制的思想来实现局部抑制,尤其是当我们使用ReLU 的时候,这种侧抑制很管用。
好处
有利于增加泛化能力,做了平滑处理,识别率提高1~2%
参考文献
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Jimmy Lei Ba, Jamie Ryan Kiros, Geoffrey E. Hinton. Layer normalization.
- Group Normalization
- AlexNet中提出的LRN
- VGG:Very Deep Convolutional Networks for Large-Scale Image Recognition
- BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm总结
- Fast Algorithms for Convolutional Neural Networks
优化
梯度下降法(Gradient Descent)
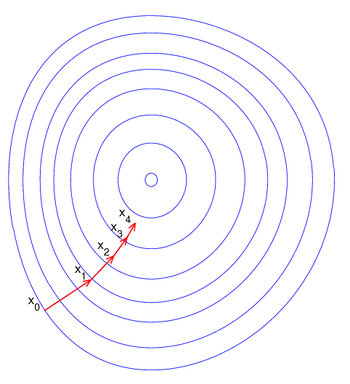
梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下降法的解是全局解。 一般情况下,其解不保证是全局最优解,梯度下降法的速度也未必是最快的。梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向, 因为该方向为当前位置的最快下降方向,所以也被称为是"最速下降法"。最速下降法越接近目标值,步长越小,前进越慢。 梯度下降法的搜索迭代示意图如下图所示:
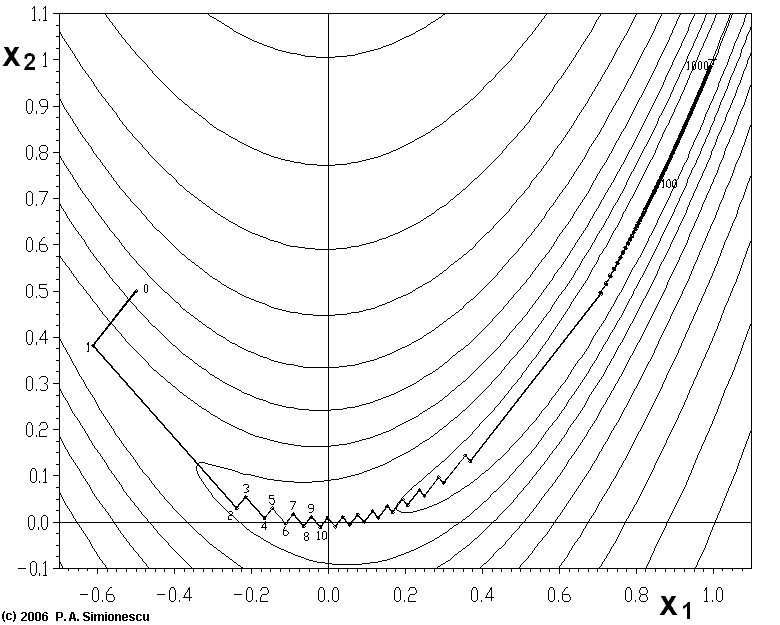
梯度下降法的缺点: * 靠近极小值时收敛速度减慢,如下图所示; * 直线搜索时可能会产生一些问题; * 可能会“之字形”地下降。
参考文献
其他参考文献
深度学习教程
CS231n: Convolutional Neural Networks for Visual Recognition.
计算平台
常用数据集合
https://www.analyticsvidhya.com/blog/2018/03/comprehensive-collection-deep-learning-datasets/ 这里我们列出了一组高质量的数据集,研究这些数据集将使你成为一个更好的数据科学家。 我们可以使用这些数据集来学习各种深度学习技术,也可以使用它们来磨练您的技能,理解如何识别和构造每个问题,考虑独特的应用场景!
图像类
| dataset名称 | 大小 | State-of-Art | 描述 |
|---|---|---|---|
| MNIST | 50MB | Dynamic Routing Between Capsules | 手写数字识别,包含60000个训练数据及10000个测试数据,可分为10类 |
| MSCOCO | ~25G | Mask RCNN | COCO is a large-scale and rich for object detection, segmentation and captioning dataset. 330K images, 1.5 million object instances, 80 object categories, 5 captions per image, 250,000 people with key points |
| ImageNet | 150GB | ResNeXt | ImageNet is a dataset of images that are organized according to the WordNet hierarchy. WordNet contains approximately 100,000 phrases and ImageNet has provided around 1000 images on average to illustrate each phrase. Number of Records: Total number of images: ~1,500,000; each with multiple bounding boxes and respective class labels |
| Open Image Dataset | 500GB | ResNet | 一个包含近900万个图像URL的数据集。 这些图像拥有数千个类别及边框进行了注释。 该数据集包含9,011219张图像的训练集,41,260张图像的验证集以及125,436张图像的测试集。 |
| VisualQA | 25GB | Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge | 图像的问答系统数据集 265,016 images, at least 3 questions per image, 10 ground truth answers per question |
| The Street View House Numbers(SVHN) | 2.5GB | Distributional Smoothing With Virtual Adversarial Training | 门牌号数据集,可用来做物体检测与识别 |
| CIFAR-10 | 170MB | ShakeDrop regularization | 图像识别数据集,包含 50000张训练数据,10000张测试数据,可分为10类 |
| Fashion-MNIST | 30MB | Random Erasing Data Augmentation | 包含60000训练样本和10000测试样本的用于服饰识别的数据集,可分为10类。 |
自然语言处理类
| dataset名称 | 大小 | State-of-Art | 描述 |
|---|---|---|---|
| IMDB 影评数据 | 80MB | Learning Structured Text Representations | 可以实现对情感的分类,除了训练集和测试集示例之外,还有更多未标记的数据。原始文本和预处理的数据也包括在内。25,000 highly polar movie reviews for training, and 25,000 for testing |
| Twenty Newsgroups | 20MB | Very Deep Convolutional Networks for Text Classification | 包含20类新闻的文章信息,内类包含1000条数据 |
| Sentiment140 | 80MB | Assessing State-of-the-Art Sentiment Models on State-of-the-Art Sentiment Datasets | 1,60,000 tweets,用于情感分析的数据集 |
| WordNet | 10MB | Wordnets: State of the Art and Perspectives | 117,000 synsets is linked to other synsets by means of a small number of “conceptual relations. |
| Yelp点评数据集 | 2.66GB JSON文件,2.9GB SQL文件,7.5GB图片数据 | Attentive Convolution | 包括470万条用户评价,15多万条商户信息,20万张图片,12个大都市。此外,还涵盖110万用户的100万条tips,超过120万条商家属性(如营业时间、是否有停车场、是否可预订和环境等信息),随着时间推移在每家商户签到的总用户数。 |
| 维基百科语料库(英语) | 20MB | Breaking The Softmax Bottelneck: A High-Rank RNN language Model | 包含4400000篇文章 及19亿单词,可用来做语言建模 |
| 博客作者身份语料库 | 300MB | Character-level and Multi-channel Convolutional Neural Networks for Large-scale Authorship Attribution | 从blogger.com收集到的19,320名博主的博客,其中博主的信息包括博主的ID、性别、年龄、行业及星座 |
| 各种语言的机器翻译数据集 | 15GB | Attention Is All You Need | 包含英-汉、英-法、英-捷克、英语- 爱沙尼亚、英 - 芬兰、英-德、英 - 哈萨克、英 - 俄、英 - 土耳其之间互译的数据集 |
语音类
| dataset名称 | 大小 | State-of-Art | 描述 |
|---|---|---|---|
| Free Spoken Digit Dataset | 10MB | Raw Waveform-based Audio Classification Using Sample-level CNN Architectures | 数字语音识别数据集,包含3个人的声音,每个数字说50遍,共1500条数据 |
| Free Music Archive (FMA) | 1000GB | Learning to Recognize Musical Genre from Audio | 可以用于对音乐进行分析的数据集,数据集中包含歌曲名称、音乐类型、曲目计数等信息。 |
| Ballroom | 14GB | A Multi-Model Approach To Beat Tracking Considering Heterogeneous Music Styles | 舞厅舞曲数据集,可对舞曲风格进行识别。 |
| Million Song Dataset | 280GB | Preliminary Study on a Recommender System for the Million Songs Dataset Challenge | Echo Nest提供的一百万首歌曲的特征数据.该数据集不包含任何音频,但是可以使用他们提供的代码下载音频 |
| LibriSpeech | 60GB | Letter-Based Speech Recognition with Gated ConvNets | 包含1000小时采样频率为16Hz的英语语音数据及所对应的文本,可用作语音识别 |
| VoxCeleb | 150MB | VoxCeleb: a large-scale speaker identification dataset]() | 大型的说话人识别数据集。 它包含约1,200名来自YouTube视频的约10万个话语。 数据在性别是平衡的(男性占55%)。说话人跨越不同的口音,职业和年龄。 可用来对说话者的身份进行识别。 |
Analytics Vidhya实践问题
- Twitter情绪分析
- 描述:识别是否包含种族歧视及性别歧视的推文。
- 大小:3MB
- 31,962 tweets
- 印度演员的年龄识别数据集
- 描述:根据人的面部属性,识别人的年龄的数据集。
- 大小:48MB
- 19,906 images in the training set and 6636 in the test set
- 城市声音分类数据集
- 描述:该数据集包含来自10个类的城市声音的8732个标记的声音片段,每个片段时间小于4秒。
- 大小:训练数据集3GB,训练数据集2GB。
- 8732 labeled sound excerpts (<=4s) of urban sounds from 10 classes