中文文本纠错
背景介绍
依赖条件
纠错技术相对于词法分析,句法分析等受到的关注一直较小,一方面是因为文本出错的比例比较小,在一些重要场合,也有专门人员进行校验;另一方面本身问题也相对较难,其要求计算机对语言规则以及文本语义有深刻的理解。
我们把中文常见错误总结分为三类:
- 用词错误,由于输入法等原因导致的选词错误,其主要表现为音近,形近等;
- 文法/句法错误,该类错误主要是由于对语言不熟悉导致的如多字、少字、乱序等错误,其错误片段相对较大;
- 知识类错误,该类错误可能由于对某些知识不熟悉导致的错误,要解决该类问题,通常得引入外部知识、常识等。
发展历程
- 2000年以前,业界主要依靠长期积累的纠错规则和纠错词典来进行纠错,比如微软的文档编辑产品WORD即采用这种方法
- 随着机器学习技术的发展,纠错问题受到了学术界和工业界越来越多的关注,其中有两大主流方法:
- 一种解决思路是将语言错误归类,然后采用Maxent(最大熵模型)、SVM等分类方法对这些类别进行重点识别;
- 另外一种思路是借鉴统计机器翻译(SMT)的思想,将语言纠错等价为机器翻译的过程,即错误文本翻译为正确文本,并随之出现了一系列的优化方法。
调研的必要性
近年来,随着新媒体行业的快速发展,中国自媒体从业人数逐年增长,至2017年有近260万。但是相对于传统媒体,其缺少人工校稿环节,编辑好的文章即刻发表,导致文章的错误比例较高。比如一些新媒体平台的正文错误率在2%以上,标题错误率在1%左右。同时,语音智能硬件产品的兴起,也暴露出语音识别技术的错误率高企问题,在某些场景语音识别中,错误率可能达到8%-10%,影响了后续的query理解及对话效果。因此研发优质的中文纠错技术,便成为了必须。
常见错误类型
在中文中,常见的错误类型大概有如下几类:
由于字音字形相似导致的错字形式:体脂称—>体脂秤 多字错误:iphonee —> iphone 少字错误:爱有天意 --> 假如爱有天意 顺序错误: 表达难以 --> 难以表达 ## 纠错组成模块 纠错一般分两大模块:
错误检测:识别错误发生的位置
错误纠正:对疑似的错误词,根据字音字形等对错词进行候选词召回,并且根据语言模型等对纠错后的结果进行排序,选择最优结果。
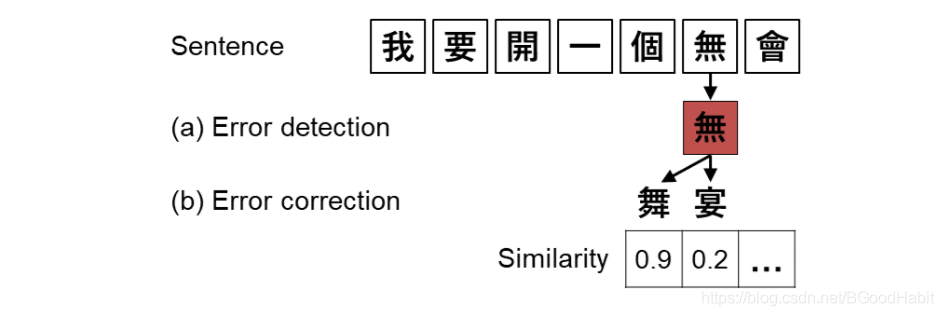
数据集
1、Academia Sinica Balanced Corpus (ASBC for short hereafter, cf. Chen et al., 1996). 2、混淆词数据集[^A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check]
[^A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check]: Wang, D. , Song, Y. , Li, J. , Han, J. , & Zhang, H. . (2018). A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. https://aclanthology.org/D18-1273.pdf
3、Chinese Grammatical Error Diagnosis NLPTEA 2016 Shared Task: http://ir.itc.ntnu.edu.tw/lre/nlptea16cged.htm NLPTEA 2015 Shared Task: http://ir.itc.ntnu.edu.tw/lre/nlptea15cged.htm NLPTEA 2014 Shared Task: http://ir.itc.ntnu.edu.tw/lre/nlptea14cfl.htm
4、Chinese Spelling Check SIGHAN 2015 Bake-off: http://ir.itc.ntnu.edu.tw/lre/sighan8csc.html CLP 2014 Bake-off: http://ir.itc.ntnu.edu.tw/lre/clp14csc.html SIGHAN 2013 Bake-off: http://ir.itc.ntnu.edu.tw/lre/sighan7csc.html
http://nlp.ee.ncu.edu.tw/resource/csc.html
赛事
几届中文纠错评测,例如CGED与NLPCC
- Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013 [Wu et al., 2013]1
- CLP-2014 Chinese Spelling Check Evaluation (Yu et al., 2014)
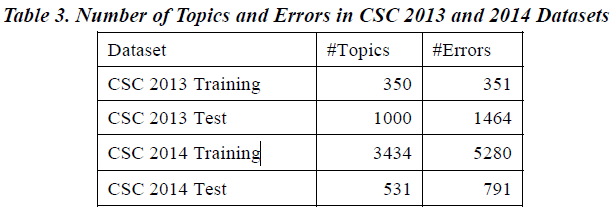
数据-构造方法
1、对字进行增删、交换位置、混淆词替换 2、常见混淆集整理 > 视觉上和语音上的相似字是造成汉语文本错误的主要因素。通过定义适当的相似性度量,考虑扩展仓颉代码,我们可以在几分之一秒内识别视觉上相似的字符。根据汉语词汇中单个汉字的发音信息,我们可以计算出一个与给定汉字在语音上相似的汉字列表。我们收集了网络上出现的621个错误的中文词汇,并分析了这些错误的原因。其中83%的错误与语音相似性有关,48%的错误与所涉及的字符之间的视觉相似性有关。生成语音和视觉上相似的字符列表,我们的程序能够包含报告错误中超过90%的错误字符。2
3、基于说文解字、四角码计算[^Using Confusion Sets and N-gram Statistics]
[^Using Confusion Sets and N-gram Statistics]: Lin C J, Chu W C. A Study on Chinese Spelling Check Using Confusion Sets and N-gram Statistics[J]. International Journal of Computational Linguistics & Chinese Language Processing, Volume 20, Number 1, June 2015-Special Issue on Chinese as a Foreign Language, 2015, 20(1).
评估-编辑距离
编辑距离的经典应用就是用于拼写检错,如果用户输入的词语不在词典中,自动从词典中找出编辑距离小于某个数\(n\)的单词,让用户选择正确的那一个,\(n\)通常取到2或者3。
这个问题的难点在于,怎样才能快速在字典里找出最相近的单词?可以像 使用贝叶斯做英文拼写检查里是那样,通过单词自动修改一个单词,检查是否在词典里,这样有暴力破解的嫌疑,是否有更优雅的方案呢?
1973年,Burkhard和Keller提出的BK树有效地解决了这个问题。BK树34的核心思想是: > 令\(d(x,y)\)表示字符串x到y的Levenshtein距离,那么显然: > \(d(x,y) = 0\) 当且仅当 \(x=y\) (Levenshtein距离为0 <==> 字符串相等) > \(d(x,y) = d(y,x)\) (从x变到y的最少步数就是从y变到x的最少步数) > \(d(x,y) + d(y,z) >= d(x,z)\) (从x变到z所需的步数不会超过x先变成y再变成z的步数)
最后这一个性质叫做三角形不等式。就好像一个三角形一样,两边之和必然大于第三边。
[^]:
技术调研
整体上,将纠错流程,分解为错误检测、候选召回、纠错排序三个关键步骤。通过引入语言知识、上下文理解和知识计算的核心技术,提升不同类型错误的解决能力。最后,支持SMT
based和NMT based两套Framework,形成完整的系统架构。 ###
关键步骤(错误检测->候选召回->纠错排序) 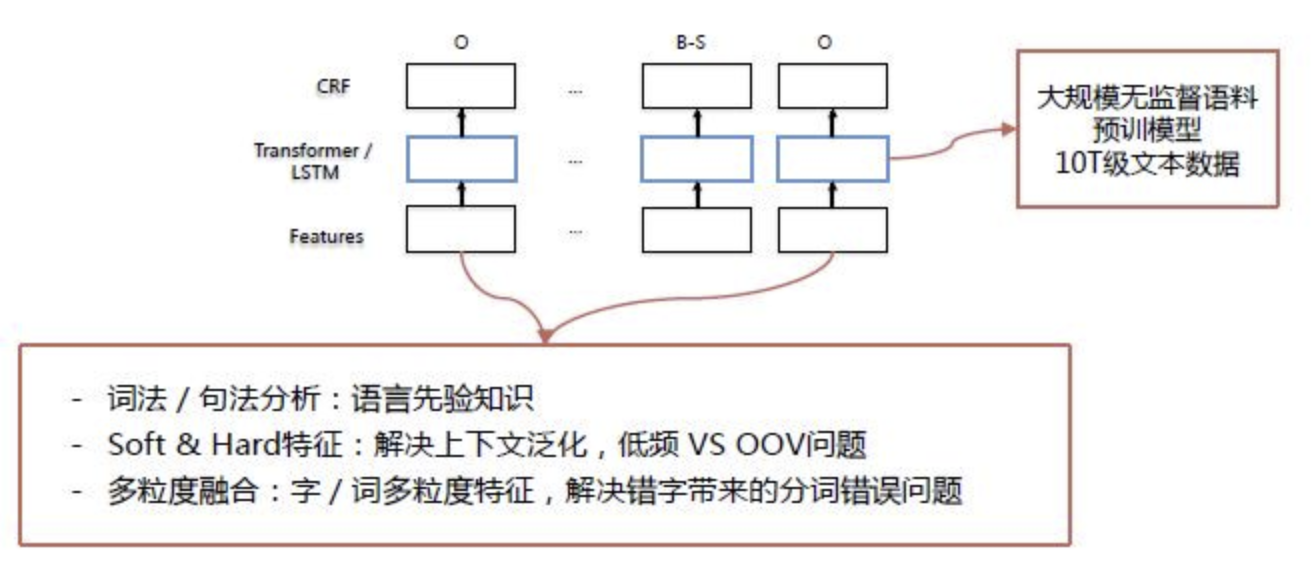
错误检测的目标是识别输入句子可能存在的问题,采用序列表示(Transformer/LSTM)+CRF的序列预测模型,这个模型的创新点主要包括:
- 词法/句法分析等语言先验知识的充分应用; -
特征设计方面,除了DNN相关这种泛化能力比较强的特征,还结合了大量hard统计特征,既充分利用DNN模型的泛化能力,又对低频与OOV(Out
of Vocabulary)有一定的区分; -
最后,根据字粒度和词粒度各自的特点,在模型中对其进行融合,解决词对齐的问题。
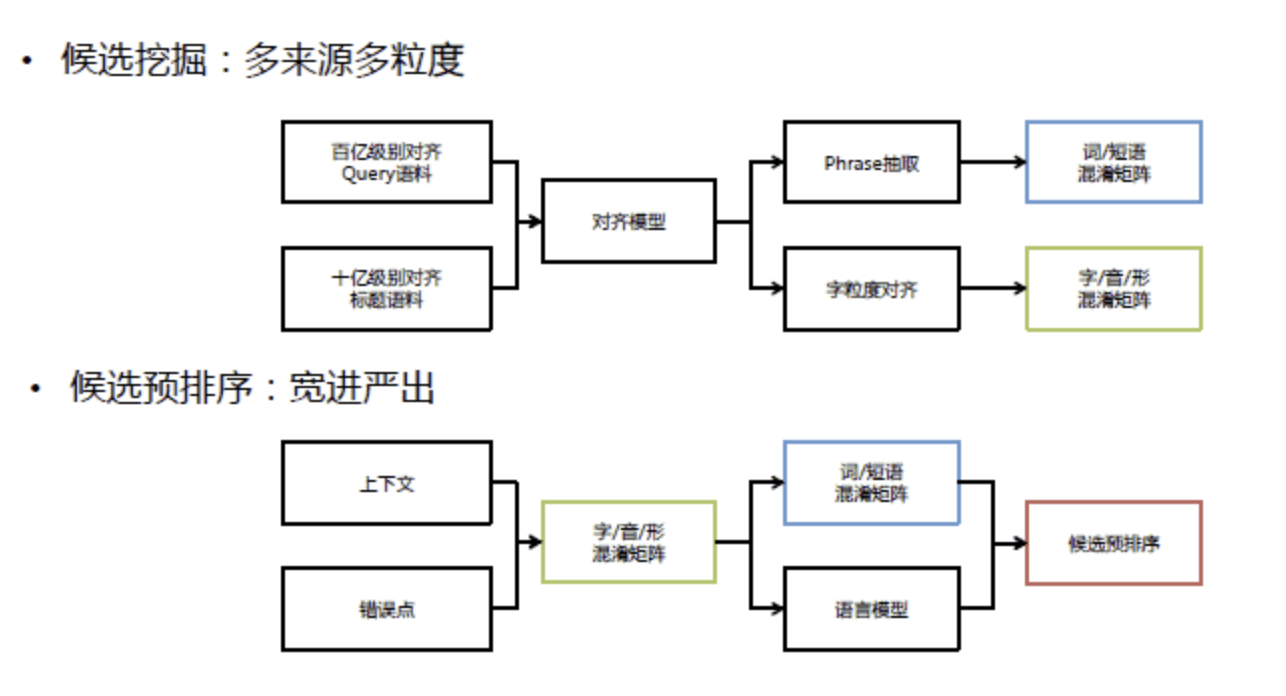
候选召回指的是,识别出具体的错误点之后,需要进行错误纠正,为了达到更好的效果以及性能,需要结合历史错误行为,以及音形等特征召回纠错候选。主要可分为两部分工作:离线的候选挖掘,在线的候选预排序。离线候选挖掘利用大规模多来源的错误对齐语料,通过对齐模型,得到不同粒度的错误混淆矩阵。在线候选预排序主要是针对当前的错误点,对离线召回的大量纠错候选,结合语言模型以及错误混淆矩阵的特征,控制进入纠错排序阶段的候选集数量与质量。
核心技术(语言知识->上下文理解->知识计算)
采用语言统计模型纠错+先验规则
- 优点:快,准
- 缺点:数据依赖性强,可拓展性弱
采用翻译技术纠错
优点:将纠错当做翻译任务去做,可以对不同类型的错误形式:错词,少词,多词等进行纠错
缺点:模型没有对字音字形相似关系的学习,纠错后的结果不受约束,很容易出现过纠错和误纠问题。
经典算法
基于统计语言模型的文本纠错方法
- 构建清洁的领域知识库,并训练统计语言模型
- 人工规则整理与混淆集收集
https://www.cnblogs.com/baobaotql/p/13358035.html
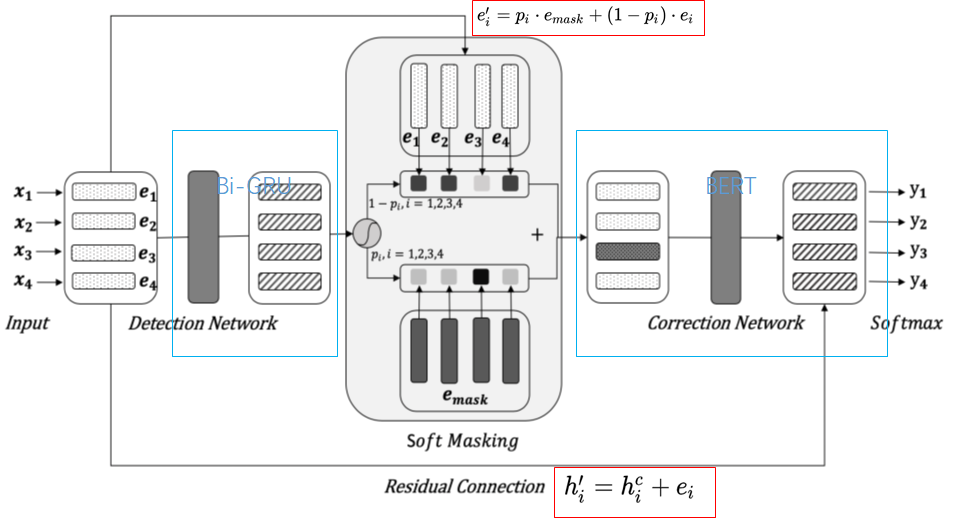
Soft-Masked BERT
Soft-Masked BERT:文本纠错与BERT的最新结合 - Bytedance - ACL 2020
给定\(n\)个字或词构成的序列\(X=(x_1, x_2,..., x_n)\),目标是把它转化为另一个相同长度的字序列\(Y=(y_1,y_2,...,y_n)\), \(X\)中的错字用正确的字替换得到\(Y\) 。该任务可看作序列标注问题,模型是映射函数\(f:X\rightarrow Y\)。
这篇文章中的纠错模型是由基于Bi-GRU序列二进制标注检测模型和基于BERT的序列多类标注纠正模型组成,
其中soft-masked embedding: \(e_i’ = p_i \cdot
e_{mask} + (1-p_i) \cdot e_i\)
可以实现将错字概率传递给后续纠正网络,使得纠正网络专注在预测正确字上。
https://zhuanlan.zhihu.com/p/144995580
https://github.com/gitabtion/SoftMaskedBert-PyTorch
基于PtrNet的错误文本检测
[^ConfusionSet +PtrNet]: https://www.aclweb.org/anthology/P19-1578.pdf "Confusionset-guided Pointer Networks for Chinese Spelling Check"
- Correcting Chinese Spelling Errors with Phonetic Pre-training
- Dynamic Connected Networks for Chinese Spelling Check
https://github.com/gitabtion/BertBasedCorrectionModels
文本语法错误纠错
Encoder-Decoder Models Can Benefit from Pre-trained Masked Language Models in Grammatical Error Correction https://aclanthology.org/2020.acl-main.391.pdf
Do Grammatical Error Correction Models Realize Grammatical Generalization? https://arxiv.org/abs/2106.03031
https://aclanthology.org/2021.findings-acl.122.pdf "Global Attention Decoder for Chinese Spelling Error Correction"
工业界的文本纠错工作
1、腾讯云:基于语言模型的拼写纠错:https://cloud.tencent.com/developer/article/1156792 "基于语言模型的拼写纠错是关于通用汉语纠错方面的综述"
2、平安寿险AI https://zhuanlan.zhihu.com/p/159101860 是关于文本纠错技术在保险领域很好的综述性的博客
3、爱奇艺: https://blog.csdn.net/BGoodHabit/article/details/114589007#21_FASPell_20
| 模型 | 发表位置 | 创新点 | 总结 |
|---|---|---|---|
| FASPell(爱奇艺) | ACL2020 | 融合字音字形相似度分数,拟合最佳分割曲线 | |
| SpellGCN(阿里)5 | 用GCN学习字音字形关系结构向量,让错词更倾向于纠错为混淆集中的字 | ||
| Soft-Mask BERT(字节) | 增加纠错检测模块,用错误检测概率控制纠错模块,减少过纠问题 | ||
| SCFL(ebay) | seq2seq | ||
| HeadFit(加利福尼亚) | treeLSTM模型学习字形向量,取代固定的混淆集 |
业务中主要存在的问题
- 多数方案通过将字音字形信息融入到模型学习中,解决纠错问题主要因为字音字形相似等带来的错误
- 在输入连续出错等纠错问题上,还面临着很多的挑战
- 当前基于transformer等decoder在实际线上业务中部署相对困难,主要集中在解码性能上。
参考文献
Wu, S. , Liu, C. , & Lee, L. . (2014). Chinese Spelling Check Evaluation at SIGHAN Bake-off 2013. Sighan Workshop on Chinese Language Processing.↩︎
Liu, C. L. , Lai, M. H. , Tien, K. W. , Chuang, Y. H. , S.-H., W. U. , & Lee, C. Y. . (2011). Visually and phonologically similar characters in incorrect chinese words: analyses, identification, and applications. Acm Transactions on Asian Language Information Processing, 10(2), 1-39.↩︎
https://www.cnblogs.com/xiaoqi/p/BK-Tree.html↩︎
ttps://en.wikipedia.org/wiki/BK-tree↩︎
https://aclanthology.org/2020.acl-main.81.pdf SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check↩︎