FasterTransformer
FasterTransformer
框架简介
在 NLP 中,编码器和解码器是两个重要的组件,transformer 层成为这两个组件的流行架构。 FasterTransformer 为编码器和解码器实现了高度优化的转换器层以进行推理。 在 Volta、Turing 和 Ampere GPU 上,当数据和权重的精度为 FP16 时,会自动使用 Tensor Cores 的计算能力。
FasterTransformer 建立在 CUDA、cuBLAS、cuBLASLt 和 C++ 之上。 我们提供以下框架的至少一个 API:TensorFlow、PyTorch 和 Triton 1后端。 用户可以直接将 FasterTransformer 集成到这些框架中。
1、TensorRT与Faster Transformer对比2
使用原生 TensorRT 可让您在不更改代码的情况下最大程度地灵活地微调网络结构或参数,而 demoBERT 和 FasterTransformer 专注于特定网络,可能需要手动更新配置文件甚至网络更改代码。
FasterTransformer 支持可变序列长度功能,该功能对连接的输入序列运行推理以避免填充部分的计算浪费,但这需要在应用程序中进行预处理以在准备输入数据时连接输入序列。此外,FasterTransformer 为
GreedySearch和BeamSearch算法提供了 CUDA 内核,它还具有多 GPU/多节点支持,而 TensorRT 还没有这些。
如果您的 Transformer 模型不是基于任何常见架构,或者如果您调整了网络结构或参数,则应考虑直接使用 TensorRT API 运行网络。另一方面,如果你想获得最大可能的性能,并愿意在部署模型上花费更多的工程精力,那么你可以考虑使用 demoBERT 或 FasterTransformer。
| TensorRT | FasterTransformer | TensorRT OSSdemoBERT sample | |
|---|---|---|---|
| Model support | Most ONNX models | Only selected models | Only BERT |
| Usability with tweaked network structure or parameters | Simple, load from ONNX directly | Need manual updates to the code and the config files. | No |
| Uses TensorRT | Yes | No | Yes, with plug-ins |
| Supports full MHA fusion | No (will be improved in a future TensorRT version). | Yes | Yes |
| Supports GEMM+GELU fusion | Yes | No | Yes |
| Support variable sequence length without padding | No | Yes | Yes |
| Support KV-cache for autoregressive transformers | No (will be improved in a future TensorRT version). | Yes | Not Applicable for BERT |
| Supports greedy/beam search for autoregressive transformers | Usually done outside of TensorRT, such as using HuggingFace APIs | Yes, natively | Not Applicable for BERT |
| Supports multi-GPU/multi-node inference | No | Yes | No |
| Supports INT8 | Yes, but only explicit quantization mode (implicit quantization mode is functional but the performance is not guaranteed). | Yes, but only for some selected models | Yes |
2、Support Matrix3
FasterTransformer 支持的模型包括额BERT/XLNet/Encoder/Decoder/GPU/T5/SwinTransformer/Vit等
| Models | Framework | FP16 | INT8 (after Turing) | Sparsity (after Ampere) | Tensor parallel | Pipeline parallel |
|---|---|---|---|---|---|---|
| BERT | TensorFlow | Yes | Yes | - | - | - |
| BERT | PyTorch | Yes | Yes | Yes | Yes | Yes |
| BERT | Triton backend | Yes | - | - | Yes | Yes |
| XLNet | C++ | Yes | - | - | - | - |
| Encoder | TensorFlow | Yes | Yes | - | - | - |
| Encoder | PyTorch | Yes | Yes | Yes | - | - |
| Decoder | TensorFlow | Yes | - | - | - | - |
| Decoder | PyTorch | Yes | - | - | - | - |
| Decoding | TensorFlow | Yes | - | - | - | - |
| Decoding | PyTorch | Yes | - | - | - | - |
| GPT | TensorFlow | Yes | - | - | - | - |
| GPT | PyTorch | Yes | - | - | Yes | Yes |
| GPT | Triton backend | Yes | - | - | Yes | Yes |
| GPT-J | Triton backend | Yes | - | - | Yes | Yes |
| Longformer | PyTorch | Yes | - | - | - | - |
| T5 | PyTorch | Yes | - | - | Yes | Yes |
| T5 | Triton backend | Yes | - | - | Yes | Yes |
| T5 | TensorRT | Yes | - | - | Yes | Yes |
| Swin Transformer | PyTorch | Yes | Yes | - | - | - |
| Swin Transformer | TensorRT | Yes | Yes | - | - | - |
| ViT | PyTorch | Yes | Yes | - | - | - |
| ViT | TensorRT | Yes | Yes | - | - | - |
| GPT-NeoX | Triton backend | Yes | - | - | Yes | Yes |
框架优化策略
1、内核优化
首先,由于SelfAttention和CrossAttention中query的序列长度始终为1,我们使用自定义的融合多头注意力内核进行优化。
其次,我们将许多小操作融合到一个内核中。例如,AddBiasResidualLayerNorm
将添加偏差、添加前一个块的残差和层归一化的计算结合到 1 个内核中。
第三,我们优化了top k操作和采样,以加速beam search和采样。最后,为了防止重新计算之前的键和值,我们在每一步分配一个缓冲区来存储它们。虽然需要一些额外的内存使用,但我们可以节省重新计算的成本,在每一步分配缓冲区,以及连接的成本。
2、内存优化
与 BERT 等传统模型不同,GPT-3 有 1750 亿个参数,即使我们以半精度存储模型也需要 350 GB。因此,我们必须减少其他部分的内存使用量。在 FasterTransformer 中,我们将复用不同解码器层的内存缓冲区。由于 GPT-3 的层数是 96,我们只需要 1/96 的内存。
对矩阵乘法进行算法选择,通过在“硬件”级别使用不同的低级算法以数十种不同的方式执行, 可以选择不同的底层算法进行操作。
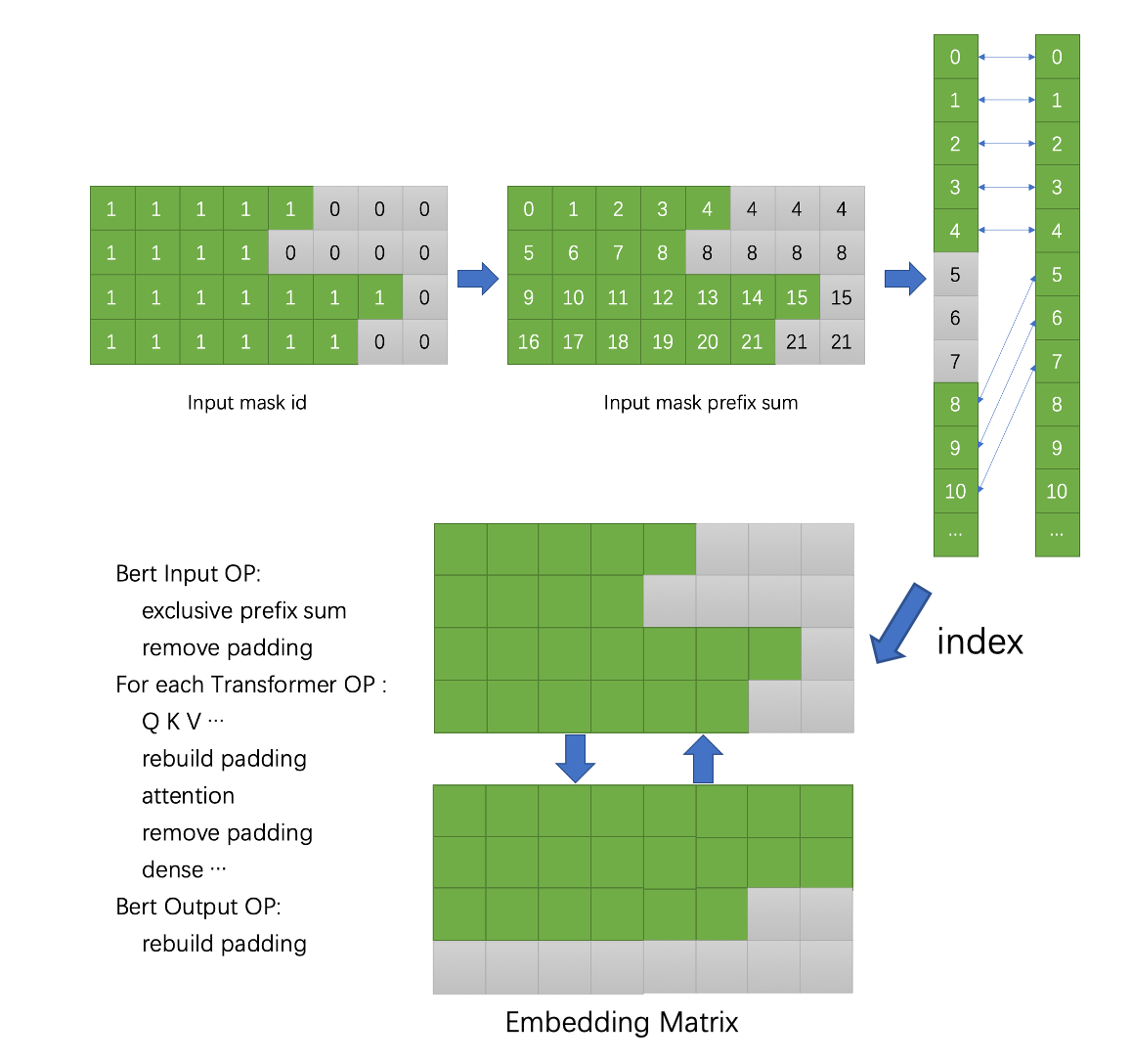
在 Effective Transformer 中,我们仍然将输入批处理作为填充矩阵,但填充值将在不同的计算阶段动态删除和恢复。通过计算输入掩码矩阵的前缀和,我们可以在没有填充值的矩阵中访问每个序列中的真实输入。 上图说明了如何访问有效输入并在计算期间动态删除和恢复填充值。 所有有效输入都显示为绿色,而填充值显示为灰色。
3、文本翻译应用集成FasterTransformer
1、模型初始化。包括decoding_gemm, MatMul
内核自动调整GEMM策略
矩阵乘法是基于Transformer的神经网络中主要和最繁重的操作。 FT 使用来自 CuBLAS 和 CuTLASS 库的功能来执行这些类型的操作。 重要的是要知道 MatMul 操作可以在“硬件”级别使用不同的低级算法以数十种不同的方式执行。
GemmBatchedEx
函数实现 MatMul 操作,并以cublasGemmAlgo_t作为输入参数。
使用此参数,您可以选择不同的底层算法进行操作。
FasterTransformer
库使用此参数对所有底层算法进行实时基准测试,并为模型的参数和您的输入数据(注意层的大小、注意头的数量、隐藏层的大小)选择最佳的一个。
此外,FT
对网络的某些部分使用硬件加速的底层函数,例如__expf__、__shfl_xor_sync
2、推理上的优化技术
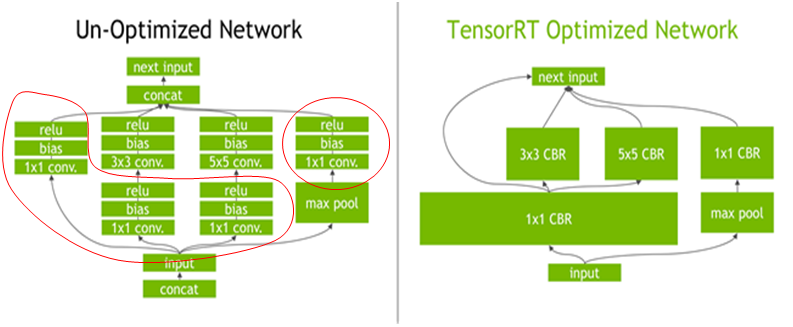
层融合——预处理阶段的一组技术,将多层神经网络组合成一个单一的神经网络,将使用一个单一的内核进行计算。 这种技术减少了数据传输并增加了数学密度,从而加速了推理阶段的计算。 例如, multi-head attention 块中的所有操作都可以合并到一个内核中。
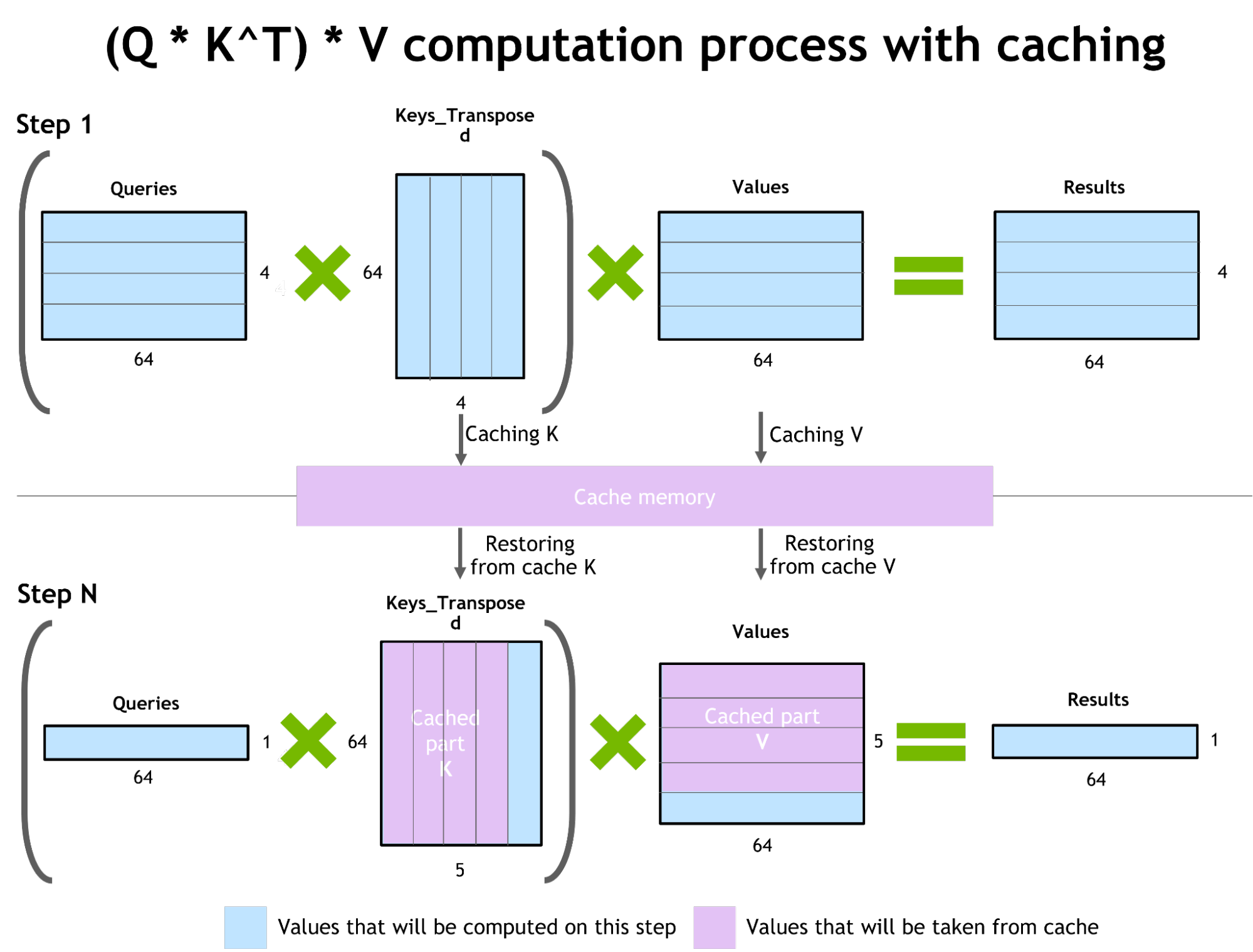
自回归模型/激活缓存
防止通过Transformer重新计算每个新token 生成器的先前键和值,FT 分配一个缓冲区来在每一步存储它们。虽然需要一些额外的内存使用,但 FT 可以节省重新计算的成本、在每一步分配缓冲区以及连接的成本。相同的缓存机制用于 NN 的多个部分。
精度较低的推理
FT 的内核支持使用 fp16 和 int8 中的低精度输入数据进行推理。 由于较少的数据传输量和所需的内存,这两种机制都允许加速。 同时,int8 和 fp16 计算可以在特殊硬件上执行,例如Tensor Core(适用于从 Volta 开始的所有 GPU 架构),以及即将推出的 Hopper GPU 中的Transformer引擎。
FAQ
1、RuntimeError: CUDA error: no kernel image is available for execution on the device
1 | [INFO] Finish the decoding gemm test |
解决过程:
网上查询说是PyTorch与CUDA版本不匹配导致的,然后我就尝试更换了基础镜像,重新安装了新的版本的pytorch,报错仍然存在。然后我又回头去看官方文档,才发现可能是我编译的时候可能传错了参数。因为我用的是T4,compute capacity为75,结果我编译的时候用的是80.
Note: the
xxof-DSM=xxin following scripts means the compute capability of your GPU. The following table shows the compute capability of common GPUs.4
| GPU | compute capacity |
|---|---|
| P40 | 60 |
| P4 | 61 |
| V100 | 70 |
| T4 | 75 |
| A100 | 80 |
| A30 | 80 |
| A10 | 86 |
参考文献
https://developer.nvidia.com/zh-cn/blog/accelerated-inference-for-large-transformer-models-using-nvidia-fastertransformer-and-nvidia-triton-inference-server/ "使用 FasterTransformer 和 Triton 推理服务器加速大型 Transformer 模型的推理"↩︎
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#transformers-performance "transformer inference tensorrt or fastertransformer"↩︎
https://raw.githubusercontent.com/NVIDIA/FasterTransformer/main/README.md "fastertransformer introduction"↩︎
https://github.com/NVIDIA/FasterTransformer.git "code"↩︎