部署AI算法服务常见FAQ
什么场景下重视latency/throughout?
推断(Inference)的实际部署有多种可能,可能部署在Data Center(云端数据中心),比如说大家常见的手机上的语音输入,目前都还是云端的,也就是说你的声音是传到云端的,云端处理好之后把数据再返回来,这种场景的服务吞吐量要高;
还可能部署在嵌入端,比如说嵌入式的摄像头、无人机、机器人或车载的自动驾驶,当然车载的自动驾驶可能是嵌入式的设备,也可能是一台完整的主机,像这种嵌入式或自动驾驶,它的特点是对实时性要求很高,这种场景下的latency要低。
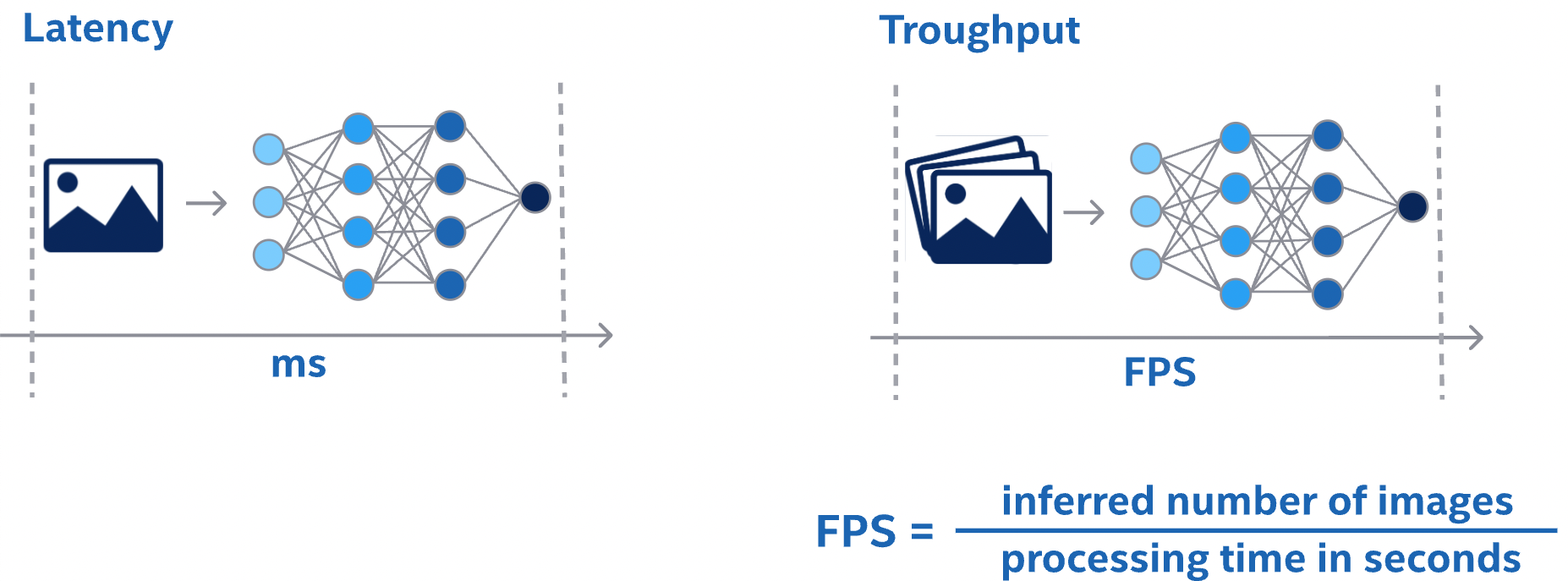
Latency
网络推理的性能度量是从输入呈现给网络到输出可用所经过的时间。这是单个推理的网络延迟。较低的延迟更好。在某些应用中,低延迟是一项关键的安全要求。在其他应用程序中,延迟作为服务质量问题对用户来说是直接可见的。对于批量处理,延迟可能根本不重要。
Throughput
另一个性能测量是在固定的时间单位内可以完成多少推理。这是网络的吞吐量。吞吐量越高越好。更高的吞吐量表明更有效地利用固定计算资源。对于批量处理,所花费的总时间将由网络的吞吐量决定。
查看延迟和吞吐量的另一种方法是确定最大延迟并在该延迟下测量吞吐量。像这样的服务质量测量可以是用户体验和系统效率之间的合理折衷。
在测量延迟和吞吐量之前,您需要选择开始和停止计时的确切点。根据网络和应用程序,选择不同的点可能是有意义的。
在很多应用中,都有一个处理流水线,整个系统的性能可以通过整个处理流水线的延迟和吞吐量来衡量。由于预处理和后处理步骤在很大程度上取决于特定应用程序,因此本节仅考虑网络推理的延迟和吞吐量
AI模型部署硬件综述
https://johneyzheng.top/posts/AI%E6%A8%A1%E5%9E%8B%E9%83%A8%E7%BD%B2%E7%A1%AC%E4%BB%B6%E7%BB%BC%E8%BF%B0/
激活函数的保险丝:RangeSupervision
深度神经网络在许多场景中都有应用,其中预测是安全相关决策的关键组成部分。此类工作负载可以受益于针对潜在错误的额外保护。例如,托管网络推理的平台中的内存位翻转(“软错误”,例如源自电路内的外部辐射或内部电气干扰)可能会破坏学习到的网络参数并导致错误的预测。通常,导致非常大的参数值的错误会对网络行为产生更剧烈的影响。此处描述的范围监督算法(“RangeSupervision”)在已经存在的激活层之后建立并插入额外的保护层。这些层会截断发现超出预期激活范围的值,以减轻潜在平台错误的痕迹。他们在推理过程中通过对
RangeSupervision 层输入中的任何激活 x
应用clamp位操作来执行此操作,
\[𝑥=𝑐𝑙𝑎𝑚𝑝(𝑥;𝑇_{𝑙𝑜𝑤},𝑇_{𝑢𝑝})=𝑚𝑖𝑛(𝑚𝑎𝑥(𝑥,𝑇_{𝑙𝑜𝑤}),𝑇_{ℎ𝑖gh})\]
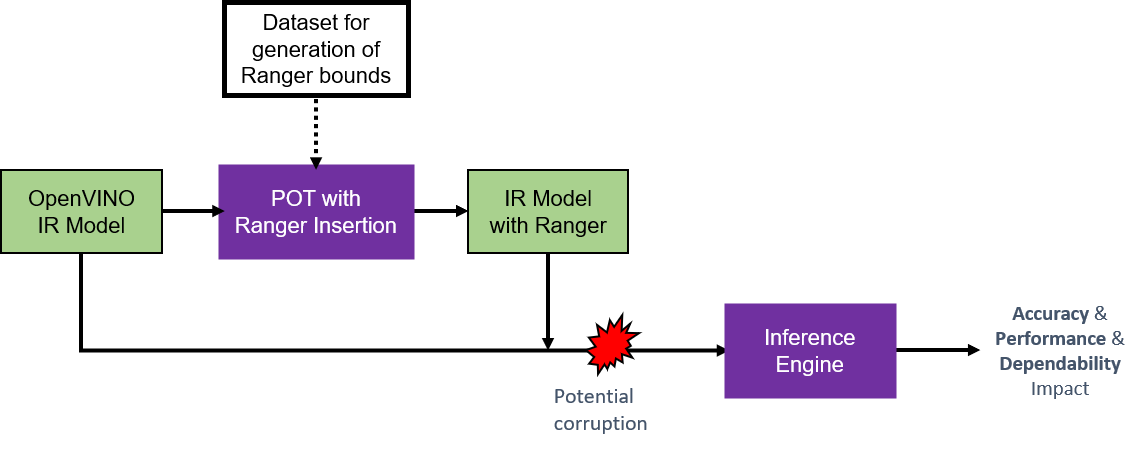
其中\(𝑇_{𝑙𝑜𝑤}\)和\(𝑇_{𝑢𝑝}\)分别是特定保护层的下限和上限。处理流程如图所示。从 OpenVINO 模型的内部表示 (IR) 开始,调用 POT RangeSupervision 算法将保护层添加到模型图中。此步骤需要从指定的测试数据集中自动提取的适当阈值。结果是模型的 IR 表示,在每个支持的激活层之后都有额外的“RangeSupervision”层。可以通过 OpenVINO 推理引擎以相同的方式调用原始模型和修改后的模型,以评估在存在潜在软错误(例如使用 benchmark_app 和 accuracy_checker 函数)的情况下对准确性、性能和可靠性的影响。该算法旨在在没有故障的情况下以可忽略的性能开销或准确性影响提供有效保护。边界提取是一次性的工作,RangeSupervision 算法返回的受保护的 IR 模型可以从那里独立使用。不需要改变网络的学习参数。
The following activation layers are currently supported for range supervision:
ReLUSwishPReLUEluGeluSigmoidTanh
This means that any activation layer of one of the above types, that the model under consideration contains, will be protected with an appropriate subsequent RangeSupervision layer