#include "onnxruntime_pybind.h" // must use this for the include of <pybind11/pybind11.h> #include <pybind11/stl.h> #include "core/providers/get_execution_providers.h"
PYBIND11_MODULE(onnxruntime_pybind11_state, m) { CreateInferencePybindStateModule(m); // move it out of shared method since training build has a little different behavior. m.def( "get_available_providers", []() -> const std::vector<std::string>& { return GetAvailableExecutionProviderNames(); }, "Return list of available Execution Providers in this installed version of Onnxruntime. " "The order of elements represents the default priority order of Execution Providers " "from highest to lowest."); } } // namespace python } // namespace onnxruntime
/** Create a new InferenceSession @param session_options Session options. @param model_uri absolute path of the model file. @param logging_manager Optional logging manager instance that will enable per session logger output using session_options.session_logid as the logger id in messages. If nullptr, the default LoggingManager MUST have been created previously as it will be used for logging. This will use the default logger id in messages. See core/common/logging/logging.h for details, and how LoggingManager::DefaultLogger works. This ctor will throw on encountering model parsing issues. */ InferenceSession(const SessionOptions& session_options, const std::string& model_uri, logging::LoggingManager* logging_manager = nullptr);
使用 CUDAExecutionProvider 时,在进行模型推理(调用
InferenceSession.Run())之前,如果输入/输出直接在目标设备(Device)上进行构造能达到性能更佳。当输入未拷贝到目标设备时,ORT
会将其从 CPU 复制到 Device,这也是在 InferenceSession.Run()
中执行。 类似地,如果输出未在设备上预先构造分配,默认情况下,ORT
直接结果输出到 CPU。尤其是当业务 Pipeline
中是多个模型时候,大部分时间花在这些数据传输上时,很明显这会占用大量的执行时间,让人以为是
ORT 性能很糟糕。例如:
1 2 3 4 5 6 7 8 9 10 11 12
import onnxruntime as ort import numpy as np import torch
providers = ["CUDAExecutionProvider"] session = ort.InferenceSession("model.onnx", providers=providers) # X is from other model output which is pytorch.Tensor X = torch.empty(shape=(3, 224, 224), dtype=torch.float32, device=torch.device("cuda:0")) io = { "X": X.detach().numpy().astype(np.float32) } Y = session.run(io)[0]
model_path = "efficientnet_b3.onnx" output_names = ['output'] dtype = np.float32 inputs = np.random.rand(1, 3, 224, 224).astype(dtype) providers = [ ('TensorrtExecutionProvider', { 'device_id': 0, 'trt_max_workspace_size': 2147483648, 'trt_fp16_enable': True, }), ('CUDAExecutionProvider', { 'device_id': 0, 'arena_extend_strategy': 'kNextPowerOfTwo', 'gpu_mem_limit': 2 * 1024 * 1024 * 1024, 'cudnn_conv_algo_search': 'EXHAUSTIVE', 'do_copy_in_default_stream': True, }), ] options = onnxruntime.SessionOptions() options.log_severity_level = 3# Applies to session load, initialization, etc. 0:Verbose, 1:Info, 2:Warning. 3:Error, 4:Fatal. Default is 2. # options.log_verbosity_level =0 # VLOG level if DEBUG build and session_log_severity_level is 0. Applies to session load, initialization, etc. Default is 0. # options.enable_cpu_mem_arena = True # options.enable_mem_pattern = True # options.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_EXTENDED # Graph optimization level for this session. options.inter_op_num_threads = 1# Sets the number of threads used to parallelize the execution of the graph (across nodes). Default is 0 to let onnxruntime choose. options.intra_op_num_threads = 1# Sets the number of threads used to parallelize the execution within nodes. Default is 0 to let onnxruntime choose. model = onnxruntime.InferenceSession(model_path, providers=providers, sess_options=options) ort_inputs = {"input": inputs} ort_outputs = [out.name for out in model.get_outputs()] results = model.run(ort_outputs, ort_inputs)[0]
常见问题
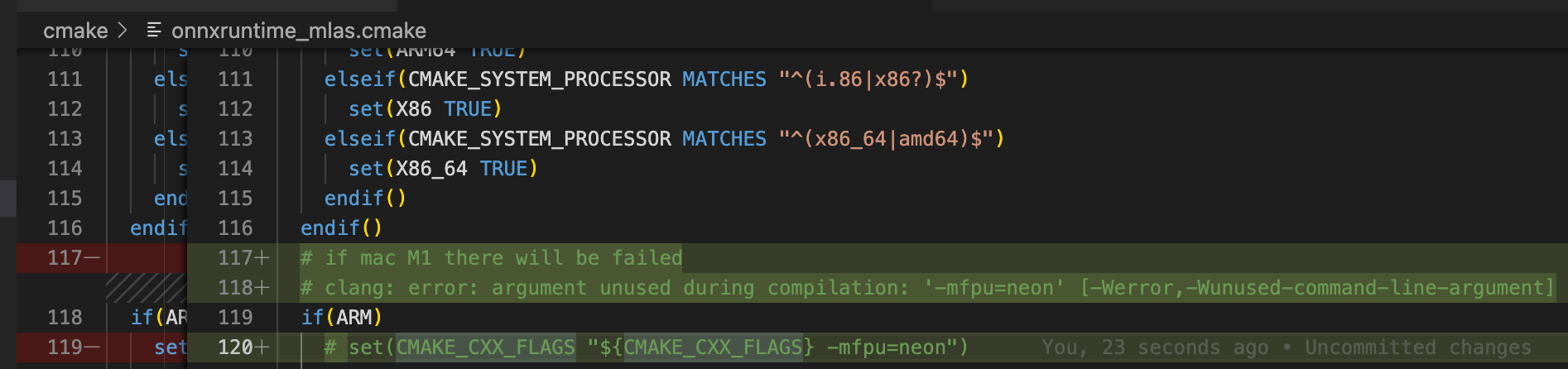
01、clang: error: argument unused during compilation: '-mfpu=neon' [-Werror,-Wunused-command-line-argument]
[ 20%] Building CXX object CMakeFiles/onnxruntime_common.dir/Users/xxx/Documents/Framework/onnxruntime/onnxruntime/core/common/cpuid_info.cc.o clang: error: argument unused during compilation: '-mfpu=neon' [-Werror,-Wunused-command-line-argument] make[2]: *** [CMakeFiles/onnxruntime_common.dir/Users/xxx/Documents/Framework/onnxruntime/onnxruntime/core/common/cpuid_info.cc.o] Error 1 make[1]: *** [CMakeFiles/onnxruntime_common.dir/all] Error 2 make: *** [all] Error 2 Traceback (most recent call last): File "/Users/xxx/Documents/Framework/onnxruntime/tools/ci_build/build.py", line 1065, in <module> sys.exit(main()) File "/Users/xxx/Documents/Framework/onnxruntime/tools/ci_build/build.py", line 1002, in main build_targets(args, cmake_path, build_dir, configs, args.parallel) File "/Users/xxx/Documents/Framework/onnxruntime/tools/ci_build/build.py", line 471, in build_targets run_subprocess(cmd_args, env=env) File "/Users/xxx/Documents/Framework/onnxruntime/tools/ci_build/build.py", line 212, in run_subprocess completed_process = subprocess.run(args, cwd=cwd, check=True, stdout=stdout, stderr=stderr, env=my_env, shell=shell) File "/Users/xxx/mambaforge/lib/python3.9/subprocess.py", line 528, in run raise CalledProcessError(retcode, process.args, subprocess.CalledProcessError: Command '['/opt/homebrew/Cellar/cmake/3.23.2/bin/cmake', '--build', '/Users/xxx/Documents/Framework/onnxruntime/build/Linux/Debug', '--config', 'Debug']' returned non-zero exit status 2.
1 2 3 4 5 6 7 8 9 10 11 12
/usr/local/lib/python3.8/dist-packages/torch/cuda/__init__.py:146: UserWarning: NVIDIA A100 80GB PCIe with CUDA capability sm_80 is not compatible with the current PyTorch installation. The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70. If you want to use the NVIDIA A100 80GB PCIe GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name)) Traceback (most recent call last): File "tools/export_onnx_models.py", line 117, in <module> convert_onnx(args.model_name, args.model_path, args.batch_size, export_fp16=args.fp16, verbose=args.verbose) File "tools/export_onnx_models.py", line 69, in convert_onnx inputs = torch.rand(batch_size, 3, 224, 224, dtype=dtype, device=0) RuntimeError: CUDA error: no kernel image is available for execution on the device
02、load
model is DataParallel format, your should notice:
the op name with 'module.' which will result some operator failed,
such as load_state_dict will throw miss match
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
# # load model weight and use another model weight update the network weight # model = EfficientNet.from_pretrained('efficientnet-b4', num_classes=5) model.set_swish(memory_efficient=False) dataparallel_model = torch.load(model_path, map_location="cpu") from collections import OrderedDict new_state_dict = OrderedDict() # method 1: use module state_dict to update weight for k in dataparallel_model.module.state_dict(): new_state_dict[k] = dataparallel_model.module.state_dict()[k]
# method 2: current dataparallel_model weight is module._xxxname for k in dataparallel_model.state_dict(): new_state_dict[k[7:]] = dataparallel_model.state_dict()[k]
WARNING: The shape inference of prim::PythonOp type is missing, so it may result in wrong shape inference for the exported graph. Please consider adding it in symbolic function. Traceback (most recent call last): File "export_onnx_efficient_cls.py", line 79, in <module> convert_onnx("efficient_b4_big_5cls", args.model_path, args.batch_size) File "export_onnx_efficient_cls.py", line 55, in convert_onnx torch.onnx.export(model.module, inputs, output_fn, verbose=verbose) File "/home/xxxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/onnx/__init__.py", line 350, inexport return utils.export( File "/home/xxxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/onnx/utils.py", line 163, inexport _export( File "/home/xxxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/onnx/utils.py", line 1110, in _export ) = graph._export_onnx( # type: ignore[attr-defined] RuntimeError: ONNX export failed: Couldn't export Python operator SwishImplementation
04、 获取onnx模型的输出
1 2 3 4 5 6 7
# get onnx output input_all = [node.name for node in onnx_model.graph.input] input_initializer = [ node.name for node in onnx_model.graph.initializer ] net_feed_input = list(set(input_all) - set(input_initializer)) assert (len(net_feed_input) == 1)
05、TypeError:
Descriptors cannot not be created directly.
Traceback (most recent call last): File "export_onnx_models.py", line 4, in <module> import onnx File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/onnx/__init__.py", line 6, in <module> from onnx.external_data_helper import load_external_data_for_model, write_external_data_tensors, convert_model_to_external_data File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/onnx/external_data_helper.py", line 9, in <module> from .onnx_pb import TensorProto, ModelProto, AttributeProto, GraphProto File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/onnx/onnx_pb.py", line 4, in <module> from .onnx_ml_pb2 import * # noqa File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/onnx/onnx_ml_pb2.py", line 33, in <module> _descriptor.EnumValueDescriptor( File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/google/protobuf/descriptor.py", line 755, in __new__ _message.Message._CheckCalledFromGeneratedFile() TypeError: Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. If you cannot immediately regenerate your protos, some other possible workarounds are: 1. Downgrade the protobuf package to 3.20.x or lower. 2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates
Traceback (most recent call last): File "export_onnx_models.py", line 148, in <module> convert_onnx(args.model_name, args.model_path, batch_size=args.batch_size, image_size=args.img_size, export_fp16=args.fp16, simplify=args.simplify, verify=args.verify, verbose=args.verbose) File "export_onnx_models.py", line 75, in convert_onnx test_infer_performance(model=model, model_name=model_name, batch_size=batch_size, input_shape=(3, image_size, image_size), num_data=10240) File "/home/xxx/Repo/infra_utilities/model_utils.py", line 72, in test_infer_performance ret = model(data) File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl return forward_call(*input, **kwargs) File "/home/xxx/Repo/infra_utilities/./models/yolox/models/yolox.py", line 30, in forward fpn_outs = self.backbone(x) File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl return forward_call(*input, **kwargs) File "/home/xxx/Repo/infra_utilities/./models/yolox/models/yolo_pafpn.py", line 98, in forward f_out0 = self.upsample(fpn_out0) # 512/16 File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1110, in _call_impl return forward_call(*input, **kwargs) File "/home/x x x/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/nn/modules/upsampling.py", line 154, in forward recompute_scale_factor=self.recompute_scale_factor) File "/home/xxx/software/miniconda3/envs/inference/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1185, in __getattr__ raise AttributeError("'{}' object has no attribute '{}'".format( AttributeError: 'Upsample' object has no attribute 'recompute_scale_factor'
[shuffleNode.cpp::symbolicExecute::392] Error Code 4: Internal Error
(Reshape_12: IShuffleLayer applied to shape tensor must have 0 or 1
reshape dimensions: dimensions were [-1,2])