ONNX:最流行的模型 IR
概述
ONNX全称为 Open Neural Network Exchange,是一种与框架无关的中间表达(IR)。ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持 ONNX。随着项目的推进,该 IR 已经被主流的推理框架所支持,逐渐发展成为最为通用的 IR。

ONNX 的数据格式
简介
ONNX本质上一种文件格式,通过Protobuf数据结构存储了神经网络结构权重。其组织格式核心定义在
Open Neural
Network Exchange Intermediate Representation (ONNX IR)
Specification,其中定义了Model/Graph/Node/ValueInfo/Tensor/Attribute
层面的数据结构。整图通过各节点(Node)的input/output指向关系构建模型图的拓扑结构。
从结果上看

1、左图
例如下面代码中应用 ONNX 表示的 mnist 模型。该模型包含一个输入 Tensor
(Input3) 和一个输出 Tensor (Plus214_Output_0),而节点 Node 0
的输入正是 Tensor Input3, 此外,该节点是 Conv
算子,该算子的属性值可以在 Attribute
中找到,而训练好的权重值(weight)Parameter5 可以在
Initializer 中找到,而每个 Node 中 ->
表示拓扑关系,通过指向关系可以构建出计算图。
1 | [W] --mode is deprecated and will be removed in Polygraphy 0.40.0. Use --show instead. |
此外,每个节点对应的 Op 可能包含一些先验参数的设置可以在 Attributes
中找到,例如 1
2
3
4
5
6
7
8
9
10Node 0 | Convolution28 [Op: Conv]
{Input3 [dtype=float32, shape=(1, 1, 28, 28)],
Initializer | Parameter5 [dtype=float32, shape=(8, 1, 5, 5)]}
-> {Convolution28_Output_0 [dtype=float32, shape=(1, 8, 28, 28)]}
---- Attributes ----
Convolution28.kernel_shape = [5, 5]
Convolution28.strides = [1, 1]
Convolution28.auto_pad = SAME_UPPER
Convolution28.group = 1
Convolution28.dilations = [1, 1]
2、右图
ONNX 不仅能表示正常训练的模型,它也包括对量化 INT8 模型表示的,例如 mnit-12-int8模型,相比较 mnit-12 模型最突出的特点是 Initializer 个数明显增多,不仅要有权重(从浮点 -> int8), 还需要额外的 scale + zero_point 参数,不仅原来的权重需要 Initializer , 相关的 Op 也需要额外的量化参数。所以 Initializer 数量增加几倍。
1 | $ polygraphy inspect model mnist-12-int8.onnx --model-type onnx --mode basic |
Proto 定义中看
Graphs
从模型 Model 定义中可以看到,一个模型中有一个 Graph 的属性。而这个 Graph的定义如下:
| Name | Type | Description |
|---|---|---|
| name | string | 计算图的名字 |
| node | Node[] | 节点列表,根据输入/输出数据依赖关系形成部分有序的计算图。它是按拓扑顺序的。 |
| initializer | Tensor[] | 张量的列表。当初始化式与图形输入具有相同的名称时,它将为该输入指定一个默认值。当初始化式的名称与所有图形输入不同时,它指定一个常量值。列表的顺序未指定。 |
| doc_string | string | 该模型的文档。 |
| input | ValueInfo[] | 计算图的输入参数,可能由' initializer '中的默认值初始化。 |
| output | ValueInfo[] | 计算图的输出参数。一旦执行写入了所有输出参数,计算图的执行就完成了。 |
| value_info | ValueInfo[] | 用于存储不是输入或输出的值的类型和形状信息。 |
原来 ValueInfo 和 Tensor 是需要从其内容信息上区分的, ValueInfo 是躯壳的话, Tensor 是具体的模型参数值。
Node
| Name | Type | Description |
|---|---|---|
| name | string | 节点的可选名称,仅用于调试目的。 |
| input | string[] | 节点用来将输入值传播到节点运算符的值的名称。 它必须引用图形输入、Initializer 或其他节点输出。 |
| output | string[] | 节点用于从节点调用的运算符捕获数据的输出的名称。它要么在图中引入一个值,要么引用一个图输出。 |
| op_type | string | 要调用的算子的符号标识符。 |
| domain | string | 算子集的命名空间,其中包含以op_type命名的操作符。 |
| attribute | Attribute[] | 命名属性,算子参数化的一种形式,用于常量值而不是传播值。 |
| doc_string | string | 该Node的文档。 |
- 计算图中的边(Edge)由一个节点的输出在后续节点的输入中按名称引用来建立。
- 给定节点的输出将新名称引入图中。节点输出的值由节点算子计算所得,节点输入可以指其他节点输出、图输入和图初始化器(Initializer)。当节点输出的名称与图输出的名称重合时,图输出的值就是该节点计算出的对应输出值。嵌套子图中的节点输入可以引用外部图中的名称(作为节点输出、图输入或图初始值设定项)。
- 该图必须对所有节点输出使用单一静态分配,这意味着所有节点输出名称在一个图中必须是唯一的。 在嵌套子图的情况下,节点输出名称必须不同于嵌套子图中可见的外部范围的名称。
- 节点间依赖性使得不能在计算图中创建循环。
- 节点中输入和输出的数量、它们的类型、节点中指定的属性集及其类型必须满足节点操作员签名施加的约束。
- 定义顶层计算图的节点列表必须按拓扑排序; 也就是说,如果节点 K 在图中跟随节点 N,则 N 的任何数据输入都不能引用 K 的输出。
- 节点属性用于将静态值传递给运算符。
更多关于数据结构的信息可以参考 standard-data-types。
ONNX支持的功能
基于ONNX模型,官方提供了一系列相关工具:模型转化/模型优化(simplifier等)/模型部署(Runtime)/模型可视化(Netron等)等
更多工具可以参考ONNX 支持的工具
1、Netron
上述图即为Netron打开
2、模型导出
torch.onnx.export 导出模型
1 | import torch |
Scikit-learn 模型导出 onnx 模型
1 | from sklearn.datasets import load_iris |
3、onnx simplifier
1 | import onnx |
simplify的基本流程如下:
step 1. 利用onnxruntime推理计算图,得到各个节点的输入输出的 infer
shape step 2.
基于ONNX支持的优化方法进行ONNX模型的优化(如fuse_bn_into_conv)
step 3. 对ONNX模型的常量OP进行折叠:
1.基于get_constant_nodes获取常量 OP
2.基于add_features_to_output将所有静态节点的输出扩展到 ONNX
图的输出节点列表中(主要为了后续步骤方便获取常量节点输出)
3.将1.中得到的常量OP从图中移除(断开连线),同时将其节点参数构建为其他节点的输入参数
4.清理图中的孤立节点(3.中断开连线的节点)
其中 v0.3.10 onnxsim/onnx_simplifier.py simplify
函数实现如下
1 | def simplify(model: Union[str, onnx.ModelProto], # onnx ModelProto object or file path |
4、onnx 模型编辑 onnx-graphsurgeon
TensorRT 官方提供了关于 onnx-graphsurgeon 操作 ONNX 模型的 example ,例如剥离子图,移除Node,子图替换等等。
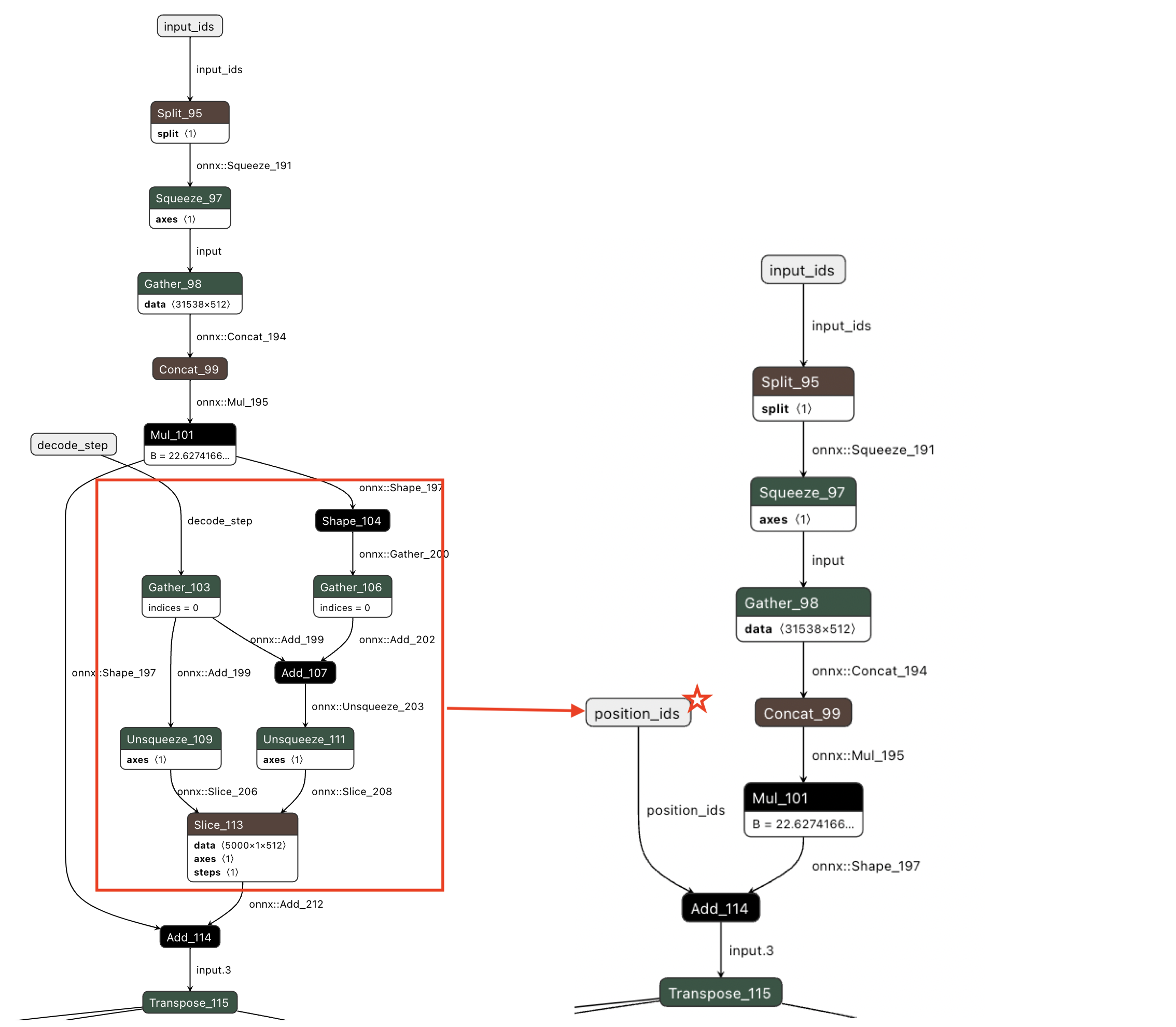
例如我们将原来的 step
这个节点进行修改,修改成直接传入已经构造好的 postion_ids
的方式:
1 | import onnx |
支持的算子
ONNX 官网 Operators
文档中列出所有 ONNX 算子。
对于每个算子,列出使用指南、参数、示例和逐行版本历史记录。 例如
Abs 是 Opset version 1 开始支持的,其中在版本号为 6 和 13
的时候进行过相关内容的变更, 要查看相信变更情况,可以进入到具体的 diff
页面进行查看;同样,Acos 是从版本 7 开始支持的。
| operator | versions | differences |
|---|---|---|
| Abs | 13, 6, 1 | 13/6, 13/1, 6/1 |
| Acos | 7 | |
| Acosh | 9 |
相关链接
- https://onnx.ai/
- https://github.com/onnx/onnx/blob/main/docs/IR.md
- https://onnx.ai/onnx/operators/index.html
- https://onnx.ai/supported-tools.html