Document
部署
tensorrt 常见问题1
| 名称 | 功能简介 | 其他 |
|---|---|---|
| netron2 | 可视化模型, 如果要临时修改模型,可以使用onnx-modifier3 | 经onnx.shape_inference推理优化后的模型,可以将结果显示在netron中 |
| onnxsim4 | 对onnx模型进行op融合,常量折叠等操作 | 部分功能也能在onnx.optim模块中找到,常用的版本为v0.3.10 |
| ploygraphy5 | 包括多种模式,实现对onnx模型的运行、优化等 | |
| trtexec6 | tensorrt官方提供的用于能够快速使用tensorrt推理模型的工具,主要功能包括对模型benchmark,构建GIE模型等 | |
| onnx_graphsurgeon7 | 常用于onnx模型裁剪、修改 | |
| NVTX+Nsight Systems | 精确查看每个op所占用的host/device时间等 |
可视化
服务压测工具
locust -f locust_file.py --host="" --headless -u 12 -r 20 -t 10m
其中locust_file.py需要如下定义: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import json
import glob
import random
import base64
from locust import HttpUser, task
fnames = list(glob.glob("./images/*"))
def build_request():
fname = random.choice(fnames)
buffer = open(fname, "rb").read()
req = json.dumps({
"image": base64.b64encode(buffer).decode("utf-8"),
})
return req
class MyUser(HttpUser):
def process(self):
req_data = build_request()
with self.client.post("/api_name", data=req_data) as res:
if res.status_code != 200:
print("Didn't get response, got: " + str(res.status_code))
自动负载均衡
gunicorn
应用 TensorRT 部署模型常用开发工具
我们总结了在使用 TensorRT 部署AI算法模型过程中常用到的几个工具:
| 名称 | 功能简介 | 其他 |
|---|---|---|
| netron | 可视化模型, 如果要临时修改模型,可以使用 onnx-modifier | 经onnx.shape_inference推理后的模型,可以将结果显示在
netron 中 |
| onnxsim | 对 ONNX 模型算子融合,常量折叠等操作 | 部分功能也能在 onnx.optim 模块中找到 |
| polygraphy | 包括多种模式,实现对 ONNX 模型的运行、优化、转换到 TensorRT 以及精度对比等功能 | |
| trtexec | TensorRT 官方提供的用于能够快速使用 TensorRT 推理模型的工具,主要功能包括对模型 benchmark ,构建 TensorRT 模型等 | |
| onnx_graphsurgeon | 常用于 ONNX 模型裁剪、修改 | |
| NVTX+Nsight Systems | NVIDIA 官方提供的针对开发过程中,CPU/GPU 时间占用等信息进行收集和分析的功能。 |
常用工具使用案例
onnx-graphsurgeon
TensorRT 官方提供了关于 onnx-graphsurgeon 操作 ONNX 模型的 example ,例如剥离子图,移除Node,子图替换等等。

例如我们将原来的 decoder_step
这个节点进行修改,修改成直接传入已经构造好的 postion_ids
的方式:
1 | import onnx |
trtexec
trtexec 工具有三个主要用途:
- 用随机或用户提供的输入数据对模型进行基准测试
- 用于生成 TensorRT 模型,例如:
1 | trtexec --onnx=output/transformer-decoder-input_mask.onnx \ |
- 基于构建器生成序列化时序缓存
polygraphy
- inspect模式下,可以查看模型结构,输入/输入信息等,例如:
1 | polygraphy inspect model identity.onnx --show layers |
1 | [I] ==== ONNX Model ==== |
- polygraphy run 模式下,查看一个 ONNX 模型是否被 TensorRT/OnnxRuntime
支持,相比较 trtexec
可以采用默认的输入,该模式下也集成了逐层对比输出结果的功能(
--validate),例如:
1 | polygraphy run transformer-init-decoder.onnx --trt |
1 | [I] RUNNING | Command: polygraphy run transformer-init-decoder.onnx --trt |
从提示信息可以看出,对于模型中的 Slice 操作,不支持动态输入的 axes 值。如果换成 ONNXRuntime 作后端,则会输出 Input/Output 等基本信息以及推理时间,最后输出 PASSED。

- convert 模式实现 ONNX 模型转为 TensorRT 模型,这个与 trtexec 功能优点类似。例如:
1 | polygraphy convert dynamic_identity.onnx -o dynamic_identity.engine \ |
- surgeon 模式下可以对模型进行常量折叠等优化。例如:
1 | polygraphy surgeon sanitize --fold-constants transformer-decoder.onnx -o transformer-decoder-fold.onnx |
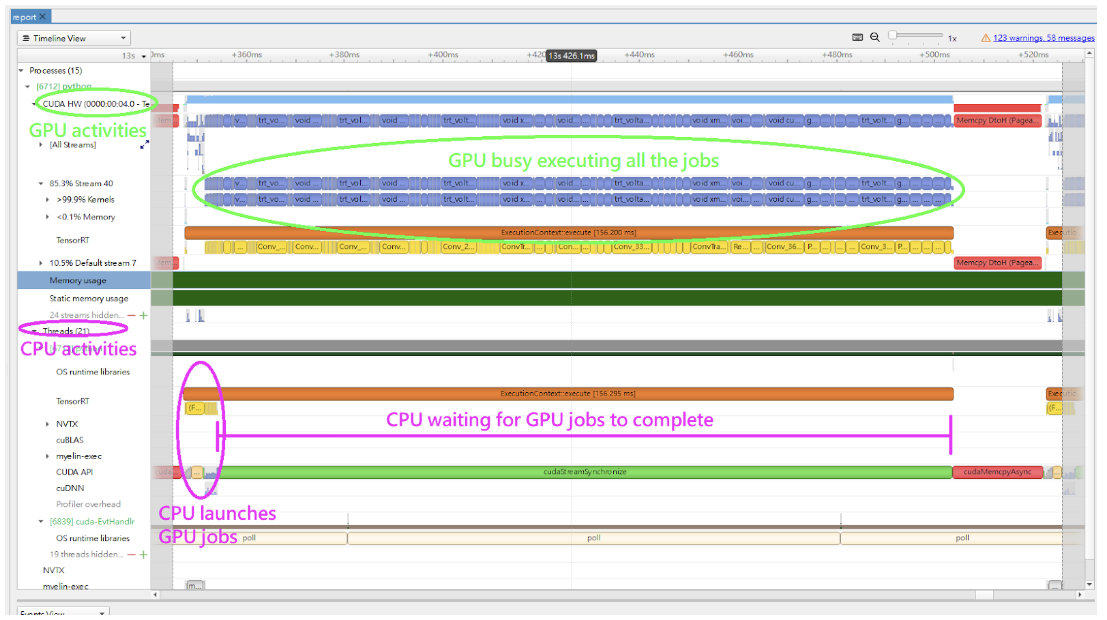
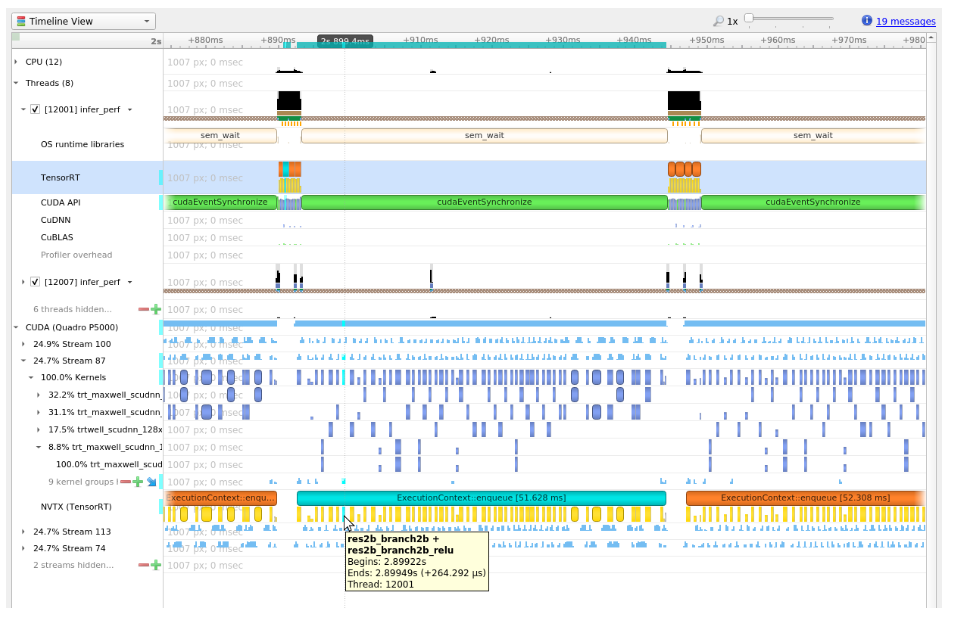
NVTX tracing+Nsight System 性能瓶颈分析
- 首先使用 trtexec 推理的时候添加
--profilingVerbosity=detailed选项
1 | trtexec --onnx=foo.onnx --profilingVerbosity=detailed --saveEngine=foo.plan |
或者在应用代码中通过IBuilderConfig进行设置,如下
1 | import tensorrt as trt |
- 然后再利用 nsys 执行模型推理过程
nsys profile -o ${nsys_output_name} --capture-range ${api_name} ${command_for_run_tensorrt_inference},例如:
1 | nsys profile -o foo_profile --capture-range cudaProfilerApi trtexec --loadEngine=foo.plan --warmUp=0 --duration=0 --iterations=50 |
- 使用 Nsight System 打开输出的结果文件, 结果中包括多种 level 多种设备上的时间占用情况,如下图所示:
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#troubleshooting "tensorrt常见问题"↩︎
https://netron.app/↩︎
https://github.com/ZhangGe6/onnx-modifier↩︎
https://github.com/daquexian/onnx-simplifier↩︎
https://docs.nvidia.com/deeplearning/tensorrt/polygraphy/docs/index.html ↩︎↩︎
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#trtexec↩︎
https://docs.nvidia.com/deeplearning/tensorrt/onnx-graphsurgeon/docs/index.html "ONNX GraphSurgeon"↩︎