Object Detection Metrics
物体检测效果评估相关的定义 1
Intersection Over Union (IOU)
Intersection Over Union (IOU) is measure based on Jaccard Index that
evaluates the overlap between two bounding boxes. It requires a ground
truth bounding box \(B_{gt}\)and a
predicted bounding box \(B_p\) By
applying the IOU we can tell if a detection is valid (True Positive) or
not (False Positive).
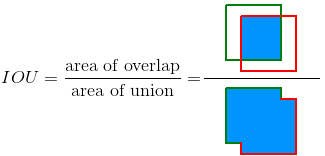
IOU is given by the overlapping area between the predicted bounding box
and the ground truth bounding box divided by the area of union between
them:
\[IOU = \frac{\text{area of overlap}}{\text{area of union}} = \frac{area(B_p \cap B_{gt})}{area(B_p \cup B_{gt})}\]
The image below illustrates the IOU between a ground truth bounding box (in green) and a detected bounding box (in red).
True Positive, False Positive, False Negative and True Negative2
Some basic concepts used by the metrics:
- True Positive (TP): A correct detection. Detection
with
IOU ≥ _threshold_ - False Positive (FP): A wrong detection. Detection
with
IOU < _threshold_ - False Negative (FN): A ground truth not detected
- True Negative (TN): Does not apply. It would represent a corrected misdetection. In the object detection task there are many possible bounding boxes that should not be detected within an image. Thus, TN would be all possible bounding boxes that were corrrectly not detected (so many possible boxes within an image). That's why it is not used by the metrics.
_threshold_: depending on the metric, it is usually set
to 50%, 75% or 95%.
Precision
Precision is the ability of a model to identify only the relevant objects. It is the percentage of correct positive predictions and is given by: \[Precision = \frac{TP}{TP + FP} = \frac{TP}{all-detections}\]
Recall
Recall is the ability of a model to find all the relevant cases (all
ground truth bounding boxes). It is the percentage of true positive
detected among all relevant ground truths and is given by: \[Recall = \frac{TP}{TP + FN} =
\frac{TP}{all-groundtruths}\] 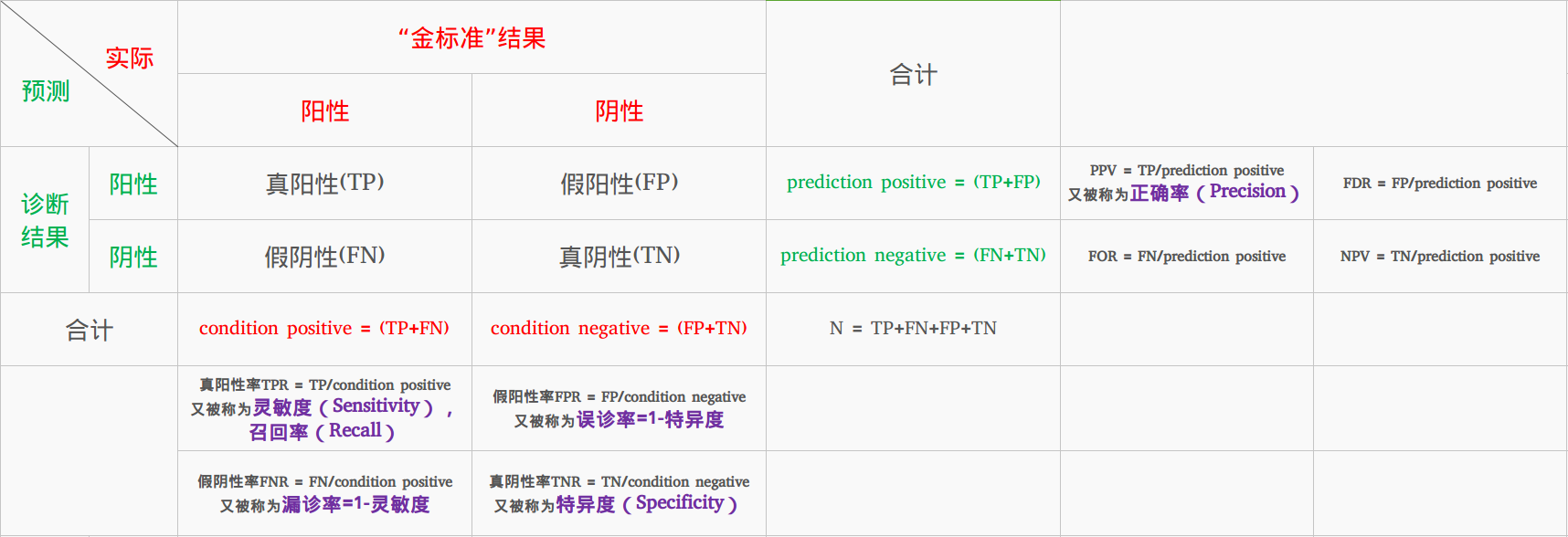
评估方法Metrics345
- Receiver operating characteristics (ROC) curve
- Precision x Recall curve
- Average Precision
- 11-point interpolation
- Interpolating all points
物体检测中的损失函数
【机器学习者都应该知道的五种损失函数!】 我们假设有\(n\)个样本, 其中\(x_i\)的gt值为\(y_i\), 算法\(f(x)\)的预测结果为\(y_i^p\)
均方误差 —— L2损失
均方误差(MSE)是回归损失函数中最常用的误差,它是预测值与目标值之间差值的平方和,公式如下
\[MSE = \frac{\sum_{i=1}^{n}(y_i - y_i^p)^2}{n}\]
平均绝对误差——L1损失函数
平均绝对误差(MAE)是另一种常用的回归损失函数,它是目标值与预测值之差绝对值的和,表示了预测值的平均误差幅度,而不需要考虑误差的方向(注:平均偏差误差MBE则是考虑的方向的误差,是残差的和),范围是0到\(\infin\)
\[MAE = \frac{\sum_{i=1}^{n}|y_i - y_i^p|}{n}\]
L1 v.s L2损失函数6
通常,利用均方差更容易求解,但平方绝对误差则对于异常值更稳健。
下面让我们对这两种损失函数进行具体的分析。无论哪一种机器学习模型,目标都是找到能使目标函数最小的点。在最小值处每一种损失函数都会得到最小值。
由于均方误差(MSE)在误差较大点时的损失远大于平均绝对误差(MAE),它会给异常值赋予更大的权重,模型会全力减小异常值造成的误差,从而使得模型的整体表现下降。所以当训练数据中含有较多的异常值时,平均绝对误差(MAE)更为有效。当我们对所有观测值进行处理时,如果利用MSE进行优化则我们会得到所有观测的均值,而使用MAE则能得到所有观测的中值。与均值相比,中值对于异常值的鲁棒性更好,这就意味着平均绝对误差对于异常值有着比均方误差更好的鲁棒性。
但MAE也存在一个问题,特别是对于神经网络来说,它的梯度在极值点处会有很大的跃变,及时很小的损失值也会长生很大的误差,这很不利于学习过程。为了解决这个问题,需要在解决极值点的过程中动态减小学习率。MSE在极值点却有着良好的特性,及时在固定学习率下也能收敛。MSE的梯度随着损失函数的减小而减小,这一特性使得它在最后的训练过程中能得到更精确的结果。
在实际训练过程中,如果异常值对于实际业务十分重要需要进行检测,MSE是更好的选择,而如果在异常值极有可能是坏点的情况下MAE则会带来更好的结果。
总结:L1损失对于异常值更鲁棒,但它的导数不连续使得寻找最优解的过程低效;L2损失对于异常值敏感,但在优化过程中更为稳定和准确。更详细的L1和L2不同比较可以参考这篇文章。
但现实中还存在两种损失都很难处理的问题。例如某个任务中90%的数据都符合目标值——150,而其余的10%数据取值则在0-30之间。那么利用MAE优化的模型将会得到150的预测值而忽略的剩下的10%(倾向于中值);而对于MSE来说由于异常值会带来很大的损失,将使得模型倾向于在0-30的方向取值。这两种结果在实际的业务场景中都是我们不希望看到的。
Huber损失——平滑平均绝对误差
Huber损失相比于平方损失来说对于异常值不敏感,但它同样保持了可微的特性。它基于绝对误差但在误差很小的时候变成了平方误差。我们可以使用超参数\(\delta\)来调节这一误差的阈值。当\(\delta\)趋向于0时它就退化成了MAE,而当\(\delta\)趋向于无穷时则退化为了MSE,其表达式如下,是一个连续可微的分段函数:
\[ L_\delta(y, f(x)) = \begin{cases} \frac{1}{2}(y - f(x))^2 & \quad \text{if } |y - f(x)| \le \delta\\ \delta{|y - f(x)|} - \frac{1}{2}\delta^2 & \quad \text{otherwise }\\ \end{cases} \]
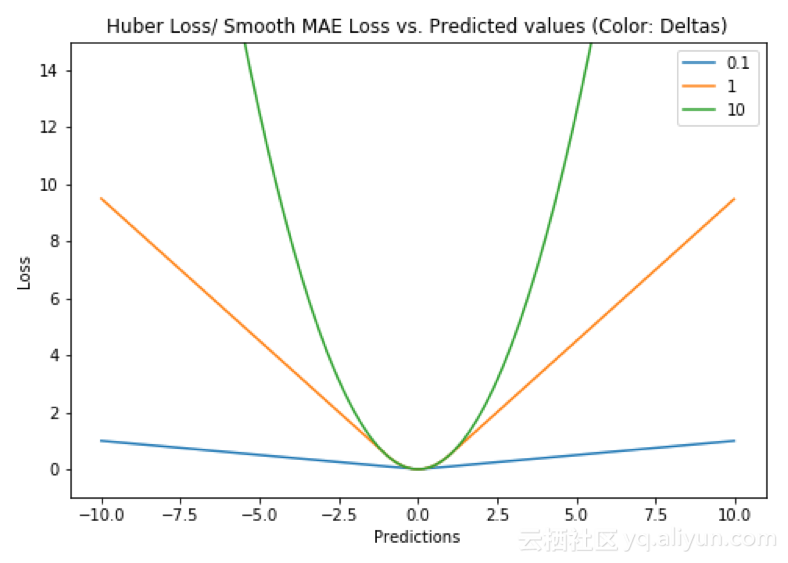
对于Huber损失来说,\(\delta\)的选择十分重要,它决定了模型处理异常值的行为。当残差大于\(\delta\)时使用L1损失,很小时则使用更为合适的L2损失来进行优化。
Huber损失函数克服了MAE和MSE的缺点,不仅可以保持损失函数具有连续的导数,同时可以利用MSE梯度随误差减小的特性来得到更精确的最小值,也对异常值具有更好的鲁棒性。
而Huber损失函数的良好表现得益于精心训练的超参数\(\delta\).
参考文献
https://github.com/cwlseu/Object-Detection-Metrics "评估标准"↩︎
https://acutecaretesting.org/en/articles/precision-recall-curves-what-are-they-and-how-are-they-used "Precision-recall curves – what are they and how are they used"↩︎
https://www.jianshu.com/p/c61ae11cc5f6 "机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率"↩︎
https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-classification-in-python/ "How and When to Use ROC Curves and Precision-Recall Curves for Classification in Python"↩︎
https://www.zhihu.com/question/30643044 "精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?"↩︎
https://yq.aliyun.com/articles/602858?utm_content=m_1000002415 "机器学习者都应该知道的五种损失函数!"↩︎
http://rishy.github.io/ml/2015/07/28/l1-vs-l2-loss/?spm=a2c4e.10696291.0.0.170b19a44a9JnP↩︎