The history of C++
C++的发展历史
C++的发展历史
应用推理引擎tensorrt部署ai算法的踩坑记录与相关技术原理学习
基于深度学习算法的的自然场景文本检测,经过几年的研究,针对解决实际问题中的某些问题,涌现出CTC, LSTM等大量的单元。在深度学习之前,已经有大量的优秀工作如SWT,MSER等算法被提出,这里我将先对一些OCR领域的经典作品进行介绍,然后再引入OCR中的深度学习算法。


Paper: Detecting Text in Natural Scenes with Stroke Width Transformgithub: https://github.com/aperrau/DetectText下面根据原文的结构和上述提供的代码详细的解读一下该算法。总的来说该算法分为四步:
* 利用canny算子检测图片的边界 * 笔画宽度变换-Stroke Width
Transform(这一步输出的图像我们称为SWT图像) *
通过SWT图像得到多个连通域 *
通过自定义的规则过滤一些连通域,得到候选连通域 *
将连通域合并得到文本行
这步不用多说,基础的图像处理知识,利用OpenCV 的Canny函数可以得到图片边缘检测的结果。
这一步输出图像和输入图像大小一样,只是输出图像像素为笔画的宽度,具体如下。

如上图所示,通过边缘检测得到上图a,假设现在从边缘上的点p开始,根据p点梯度的反方向找到边缘另一边的点q,如果p点的梯度与q点梯度的反方向夹角在\(\pm\pi/6\)之间,那么这两点间的距离为一个笔画宽度,那么p点和q点以及它们之间的像素在SWT输出图像中对应位置的值为p和q点的距离大小。
按照上述的计算方法会有两种情况需要考虑。如下图所示,

下图a表示一个笔画中的像素可能得到两个笔画宽度,这种情况下将红点出的笔画宽度设置为最小的那个值,下图b表示当一个笔画出现更为复杂情况,b图中的红点计算出的两个笔画宽度用两个红线表示,这两红线都无法真正表示笔画的宽度,这时候笔画宽度取这里面所有像素计算得到的笔画宽度的中值作为红点出的笔画宽度。
因为有文字比背景更亮和背景比文字更亮两种情况,这样会导致边缘的梯度方向相反,所以这一个步骤要执行两遍。这个步骤结束后得到一张SWT图像。
在通过上述步骤得到SWT输出图像后,该图像大小与原图像大小一致,图像中的像素值为对应像素所在笔画的宽度(下面称为SWT值)。现将相邻像素SWT值比不超过3.0的归为一个连通域。这样就能得到多个连通域。
上述步骤输出的多个连通域中,并不是所有的连通域都被认为是笔画候选区域,需要过滤一些噪声的影响,过滤的规则有: * 如果某连通域的方差过大(方差大于连通域的一半为方差过大为过大),则认为该连通域不是有效的 * 如果某连通域过大(宽大于300)或者过小(宽小于10),则认为该连通域不是有效的(代码中只过滤了过大的连通域,连通域的长宽为连通域外接矩形的长宽) * 如果某连通域的长宽比不在0.1-10的范围内,则认为该连通域不是有效的(连通域的长宽为连通域外接矩形的长宽) * 如果某连通域的外接矩形包含其他两个连通域,则认为该连通域不是有效的(代码中判定,如果某个连通域的外接矩形包含两个或两个以上连通域外接矩形的中心时,认为其包含了两个连通域) 上述条件都满足的连通域,认为是笔画候选区域,用于输入给下一步操作。
文中认为,在自然场景中,一般不会只有单个字母出现,所有将连通域合并为文本有利于进一步将噪声排除。
当两个连通域满足下面条件时,认为这两个连通域是一对: * 两个连通域中值的比小于2.0(连通域中值,指的是连通域中所有像素值的中值) * 两个连通域高的比小于2.0(连通域的高,指其外界矩形的高) * 两个连通域之间的距离小于较宽的连通域宽度的3倍(连通域之间的距离为连通域外界矩形中心点之间的距离) * 两个连通域的颜色相似(代码用两个连通域对应于原图区域的像素均值代表该连通域的颜色)
得到两两连通域组成的多对连通域后,如果有两对连通域有共享的连通域,共享的连通域都在连通域对的一端(即连通域的首端或者尾端),且方向相同(方向用一个连通域中心到另一个连通域中心的方向),就将这两对连通域合并为一个新的连通域组,依次进行,知道没有连通域对需要合并则合并结束。
最后将合并完的结果中滤除小于3的连通域的连通域组得到的最终结果,认为是一行文字。
最大稳定极值区域MSER是一种类似分水岭图像的分割与匹配算法,它具有仿射不变性。极值区域反映的就是集合中的像素灰度值总大于或小于其邻域区域像素的灰度值。对于最大稳定区域,通过局部阈值集操作,区域内的像素数量变化是最小的。
MSER的基本原理是对一幅灰度图像(灰度值为0~255)取阈值进行二值化处理,阈值从0到255依次递增。阈值的递增类似于分水岭算法中的水面的上升,随着水面的上升,有一些较矮的丘陵会被淹没,如果从天空往下看,则大地分为陆地和水域两个部分,这类似于二值图像。在得到的所有二值图像中,图像中的某些连通区域变化很小,甚至没有变化,则该区域就被称为最大稳定极值区域。这类似于当水面持续上升的时候,有些被水淹没的地方的面积没有变化。
上述做法只能检测出灰度图像的黑色区域,不能检测出白色区域,因此还需要对原图进行反转,然后再进行阈值从0~255的二值化处理过程。这两种操作又分别称为MSER+和MSER-。
MSER是当前认为性能最好的仿射不变性区域的检测方法,其使用不同灰度阈值对图像进行二值化来得到最稳定区域,表现特征有以下三点: * 对图像灰度仿射变化具有不变性, * 对区域支持相对灰度变化具有稳定性, * 对区域不同精细程度的大小区域都能进行检测。
MSER最大极值稳定区域的提取步骤: * 像素点排序 * 极值区域生成 * 稳定区域判定 * 区域拟合 * 区域归一化
序列学习任务需要从未分割的输入数据中预测序列的结果。HMM模型与CRF模型是序列标签任务中主要使用的框架,这些方法对于许多问题已经获得了较好的效果,但是它们也有缺点:
RNN网络除了输入与输出的表达方式需要选择之外不需要任何数据的先验。 它可以进行判别训练,它的内部状态为构建时间序列提供了强大的通用机制。 此外,其对时间和空间噪声具有很强的鲁棒性。
但是对于RNN呢,它是不能拿来做序列预测的,这是因为RNN只能去预测一些独立标签的分类,因而就需要进行序列预分割。要解决该问题,那么将RNN与HMM结合起来被称之为hybrid approach。在该方法中使用HMM为长序列结构数据建立模型,神经网络就提供局部分类。加入HMM之后可以使得在训练中自动分割序列,并且将原本的网络分类转换到标签序列。然而,它并没有避免上述内容中HMM使用缺点。
CTC( Connectionist Temporal Classification),可以解决前面提到的两点局限,直接使用序列进行训练。CTC引入了一个新的损失函数,可以使得RNN网络可以直接使用未切分的序列记性训练。为了使用这个损失函数, 为RNN引入其可以输出的"BLANK"标签, RNN的输出是所有标签的概率。 这里将Temporal Classification定义为\(h\),训练数据集合\(S\)中数据是成对存在的\((\mathbf{x},z)\),其中\(\mathbf{x}\)是训练的时序数据,\(z\)是标签数据。目标就是找到一个时序分类器\(h\)使得\(S\)中的\(x\)被分类到\(z\)。训练这个分类器,就需要一个错误度量,这里就借鉴了编辑(ED)距离度量,而引入了label error rate(LER)。在这里还对其进行了归一化,从而得到了如下的形式:
\[LER(h, S) = \frac{1}{Z}\sum_{(\mathbf{x},z)\in S} ED(h(\mathbf{x}))\]
将网络输出转换成为基于标签序列的条件概率,从而可以使用分类器对输入按照概率大小进行分类。
在CTC网络中拥有一个\(softmax\)输出层,其输出的个数为\(∣L∣+1\),\(L\)是标签元素的集合,额外的一个那当然就是"BLANK"标签了。这些输出定义了将所有可能的标签序列与输入序列对齐的所有可能路径的概率。任何一个标签序列的总概率可以通过对其不同排列的概率求和得到。 首先对于一条可行的路径\(p(\pi|x)\)被定义为对应路径上的各个时刻输出预测概率的乘积。其定义如下:
\[p(\pi|x) = \prod^T_{t=1}y_{\pi_t}^t, \quad \forall \pi \in L'^T\]
对于预测结果中的一条路径的标签,论文中假设这些不同时刻网络的输出是相互独立的,而这种独立性是通过输出层与自身或网络之间不存在反馈连接来确保实现的。
在此基础上还定义了映射函数\(B\),它的职责就是去除"BLANK"与重复的标签。因而给定的一个标签其输出概率就可以描述为几个可行路径相加和的形式:
\[ p(l|\mathbf{x}) = \sum_{\pi \in B^{-1}(l)} p(\pi|\mathbf{x}) \]
从上面的内容中已经得到了一个序列标签的输出条件概率,那么怎么才能找到输入数据最匹配的标签呢?最为直观的便是求解
\[h(X) = \arg\max_{l\in L \le T} p(l|\mathbf{x})\]
在给定输入情况下找到其最可能的标签序列,这样的过程使用HMM中的术语叫做解码。目前,还没有一种通过易理解的解码算法,但下面的两种方法在实践过程中也取得了不错的效果。
该方法是建立在概率最大的路径与最可能的标签时对应的,因而分类器就被描述为如下形式:
\[h(\mathbf{x}) \approx B(\pi^*)\]
\[where\quad \pi^* = \arg\max_{\pi \in N^t}p(\pi|\mathbf{x})\]
从上面的形式中就可以看出,最佳路径解码的计算式很容易的,因为最佳路径中的元素是各个时刻输出的级联。但是呢,这是不能保证找到最可能的标签的。
前缀解码在足够时间的情况下会找到最可能的标签,但是随着输入序列长度的增强时间也会指数增加。如果输入的概率分布是尖状的,那么可以在合理的时间内找到最可能的路径。
实践中,前缀搜索在这个启发式下工作得很好,通常超过了最佳路径解码,但是在有些情况下,效果不佳。
目标函数是由极大似然原理导出的。也就是说,最小化它可以最大化目标标签的对数可能性。有了损失函数之后就可以使用依靠梯度进行优化的算法进行最优化。
CTC在网络中放置在双向递归网络的后面作为序列预测的损失来源。CTC会在RNN网络中传播梯度,进而使得其学习一条好路径。
需要一种有效的方法来计算单个标签的条件概率\(p(l|\mathbf{x})\)。对于这样的问题,其实就是对应于给定标签的所有路径的综合。通常有很多这样的路径。这里我们采用动态规划的算法计算所有可能路径的概率和,其思想是,与标签对应的路径和可以分解为与标签前缀对应的路径的迭代和。 然后,可以使用递归向前和向后变量有效地计算迭代。 以下是本文设计到的一些符号定义:
\[\alpha_t(s) \overset{def}{=} \sum_{\pi \in N^T: \atop B(\pi_{1:t}) = l_{1:s}} \prod^t_{t^{\prime} = 1} y_{\pi_{t^{\prime}}}^{t^{\prime}}.\]
其中B是溢出所有"BLANK"与重复字符的变换;\({\pi \in N^T:B(\pi_{1:t}) = l_{1:s}}\) 是时刻1到t的预测矩阵中,给出经过变换\(B\)之后与标签有前s个一致的所有可行路径;\(y^{t^{\prime}}\) 是指时刻\(t^{\prime}\)时RNN的输出。而且\(\alpha_{t}(s)\)可以通过\(\alpha_{t-1}(s)\)与\(\alpha_{t-1}(s-1)\)迭代计算出来。
图3中描述的状态转移图与上面公式的含义是相同的。为了能够在输出路径中出现"BLANK"标签,将标签修改成了\(l^{\prime}\),也就是在标签的前后与字符之前插入空白标签,因而生成的标签长度就变成了\(2|l|+1\)的长度,使其可以再空白标签与非空白标签之间转换,也可以使非空白标签之间发生转换。 上面的公式1中已经给出了其计算的内容,但其计算并不具有可行性。但是可以根据图3中\(\alpha_{t}(s)\)的递归定义使用动态规划算法去解决该问题,仔细看这幅图,是不是有点像HMM的前向计算过程。
对于解决该问题使用动态规划的算法进行解决,首先来分析时刻1时候的情况:
\[\alpha_1(1) = y_b^1\]
\[\alpha_1(2) = y_{l^{\prime}}^1\]
\[\alpha_1(s) = 0, \forall s > 2\]
\[\alpha_t(s) = \begin{cases} a_t(s)y_{l_{s}^{\prime}}^t, \quad if\quad l_s^{\prime} = b\quad or\quad l_{s-2}^{\prime} = l_s^{\prime}\\ (\bar{\alpha_t}(s) +\alpha_{t-1}(s -2))y_{l_{s}^{\prime}}^t, \quad otherwise \end{cases}\]
where \(\alpha_t(s) \overset{def}{=} \alpha_{t-1}(s) + \alpha_{t-1}(s-1)\) 最后就可以得到一个序列的输出概率
\[p(l|\mathbf{x}) = \alpha_T(|l^{\prime}|) + \alpha_T(|l^{\prime}| -1)\]
反向传播的变量\(\beta_{t}(s)\)被定义为\(t\)时刻\(l_{s:|l|}\)的总概率 \[ \beta_{t}(s) \stackrel{\mathrm{def}}{=} \sum_{\pi \in N^{T} \atop \mathcal{B}(\pi_{t : T}) = l_{s:|l|}} \prod_{t^{\prime}=t}^{T} y_{\pi_{t^{\prime}}^{\prime}}^{t^{\prime}} \]
\[ \beta_{T}\left(\left|\mathbf{l}^{\prime}\right|\right)=y_{b}^{T} \\ \beta_{T}\left(\left|\mathbf{l}^{\prime}\right|-1\right)=y_{l_{|l|}}^{T} \\ \beta_{T}(s)=0, \quad \forall s<\left|\mathbf{l}^{\prime}\right|-1 \\ \beta_{t}(s)=\left\{ \begin{array}{ll}{ \overline{\beta}_{t}(s) y_{1 s}^{t}} & {\text { if } 1_{s}^{\prime}=b \text { or } 1_{s+2}^{\prime}=1_{s}^{\prime}} \\ {\left(\overline{\beta}_{t}(s)+\beta_{t+1}(s+2)\right) y_{1_{s}^{t}}} & {\text { otherwise }} \end{array} \right. \]
\[ \begin{array}{l}{ \text {where}} {\quad\overline{\beta}_{t}(s) \stackrel{\mathrm{def}}{=} \beta_{t+1}(s)+\beta_{t+1}(s+1)} \end{array} \]
最大似然训练的目的是同时最大化训练集中所有正确分类的对数概率。因而这里可以将损失函数定义为:
\[ O^{M L}\left(S, \mathcal{N}_{w}\right)=-\sum_{(\mathbf{x}, \mathbf{z}) \in S} \ln (p(\mathbf{z} | \mathbf{x})) \]
为了使用梯度进行网络训练,因而就需要对网络的输出进行微分,且训练样本是相互独立的,也就是说可以单独考虑了,因而可以将微分写为:
\[ \frac{\partial O^{M L}\left(\{(\mathbf{x}, \mathbf{z})\}, \mathcal{N}_{w}\right)}{\partial y_{k}^{t}}=-\frac{\partial \ln (p(\mathbf{z} | \mathbf{x}))}{\partial y_{k}^{t}} \]
这里可以用前向后向算法计算上式。主要思想是:对于一个标记l,在给定s和t的情况下,前向和后向变量的内积是对应l所有可能路径的概率。表达式为:
\[ \alpha_{t}(s) \beta_{t}(s)=\sum_{\pi \in \mathcal{B}^{-1}(1) : \atop {\pi_t = l_s^{\prime}}} y_{1_{s}}^{t} \prod_{t=1}^{T} y_{\pi_{t}}^{t} \]
且根据上面的公式(2)联合可以得到:
\[ \frac{\alpha_{t}(s) \beta_{t}(s)}{y_{1_{s}^{t}}^{t}}=\sum_{\pi \in \mathcal{B}^{-1}(1): \atop {\pi_t = l_s^{\prime}}} p(\pi | \mathbf{x}) \]
再与前面的公式(3)联合可以得到
\[ p(\mathbf{l} | \mathbf{x})=\sum_{s=1}^{\left|\mathbf{l}^{\prime}\right|} \frac{\alpha_{t}(s) \beta_{t}(s)}{y_{1_{s}^{\prime}}^{t}} \]
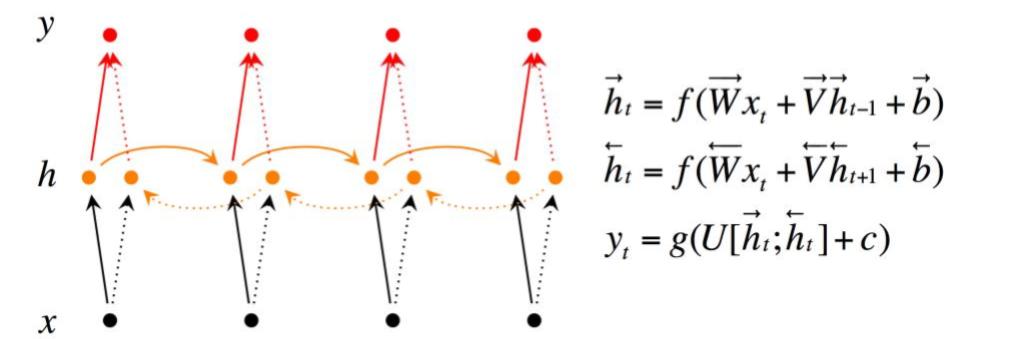
整体架构如下,其中需要用到Reverse这种Layer
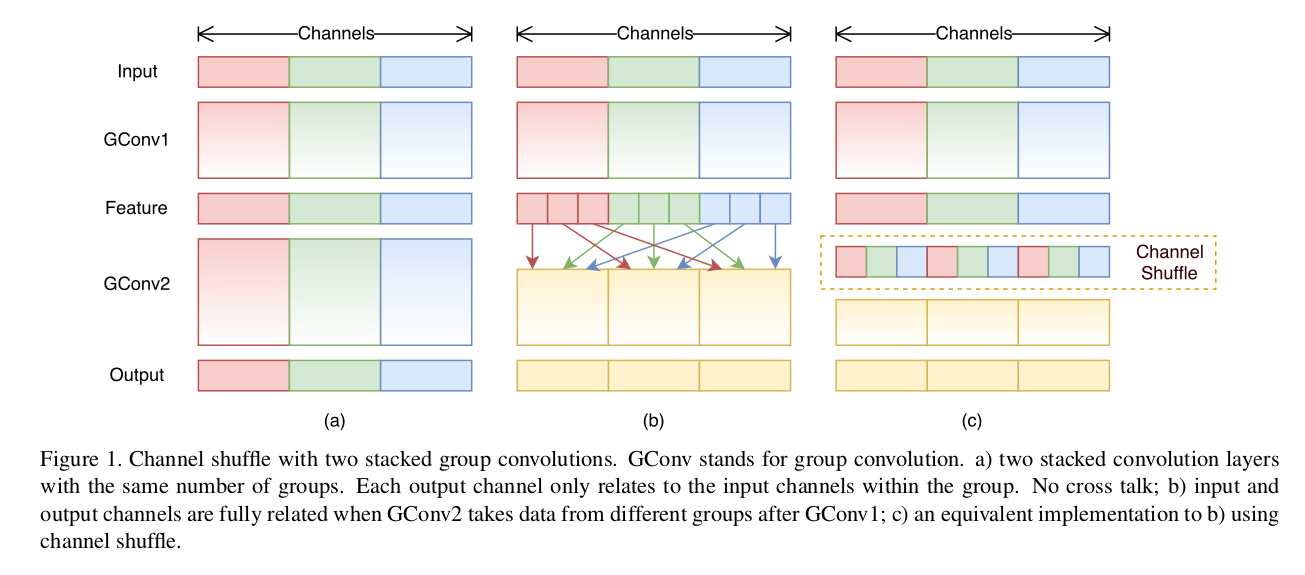
一般的分组卷积(如ResNeXt的)仅对\(3\times3\)的层进行了分组操作,然而\(1\times1\)的pointwise卷积占据了绝大多数的乘加操作,在小模型中为了减少运算量只能减少通道数,然而减少通道数会大幅损害模型精度。作者提出了对\(1\times1\)也进行分组操作,但是如图1(a)所示,输出只由部分输入通道决定。为了解决这个问题,作者提出了图(c)中的通道混淆(channel shuffle)操作来分享组间的信息,假设一个卷基层有g groups,每个group有n个channel,因此shuffle后会有\(g\times n\)个通道,首先将输出的通道维度变形为(g, n),然后转置(transpose)、展平(flatten),shuffle操作也是可导的。
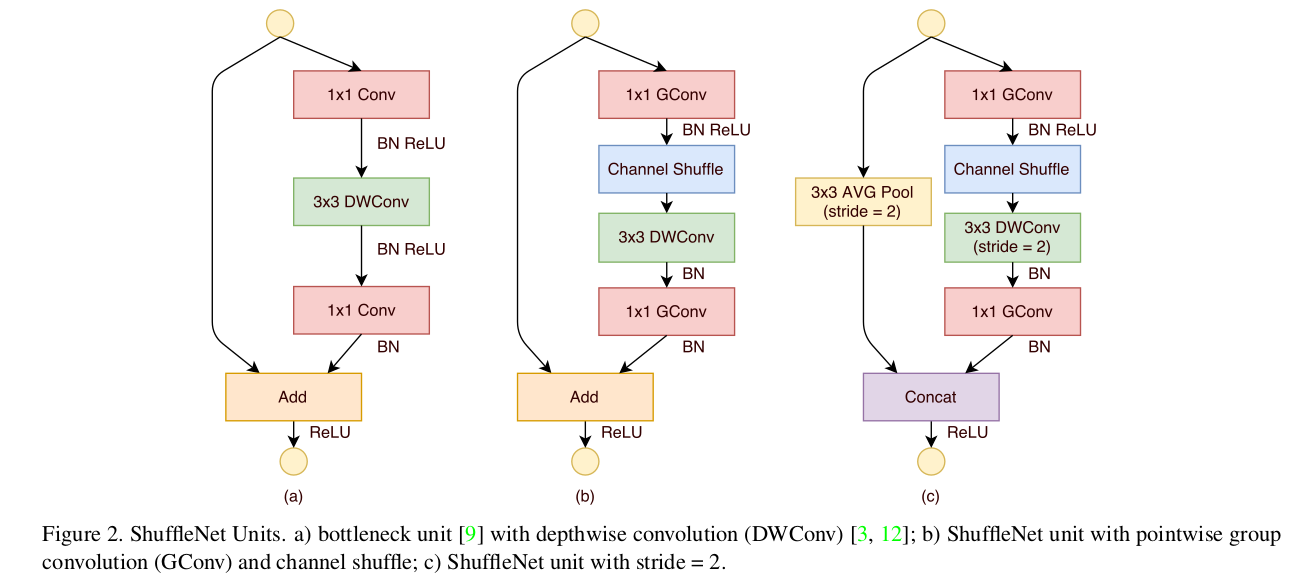
图2 (a)是一个将卷积替换为depthwise卷积7的residual block,(b)中将两个\(1\times1\)卷积都换为pointwise group convolution,然后添加了channel shuffle,为了简便,没有在第二个pointwise group convolution后面加channel shuffle。根据Xception的论文,depthwise卷积后面没有使用ReLU。(c)为stride > 1的情况,此时在shotcut path上使用\(3\times3\)的平均池化,并将加法换做通道concatenation来增加输出通道数(一般的设计中,stride=2的同时输出通道数乘2)。
对于\(c \times h \times w\)的输入大小,bottleneck channels为m,则ResNet unit需要\(hw(2cm + 9m^2)FLOPs\),ResNeXt需要\(hw(2cm + 9m^2/g)FLOPs\),ShuffleNet unit只需要\(hw(2cm/g + 9m)FLOPs\),g表示卷积分组数。换句话说,在有限计算资源有限的情况下,ShuffleNet可以使用更宽的特征图,作者发现对于小型网络这很重要。
即使depthwise卷积理论上只有很少的运算量,但是在移动设备上的实际实现不够高效,和其他密集操作(dense operation)相比,depthwise卷积的computation/memory access ratio很糟糕。因此作者只在bottleneck里实现了depthwise卷积。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes,
kernel_size, stride=1, padding=0,
dilation=1, groups=1,
relu=True, bn=True, bias=True):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU(inplace=True) if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
Commom_C = 512
anchor_k = 10
class CTPN_Model(nn.Module):
def __init__(self):
super().__init__()
base_model = models.vgg16(pretrained=False)
layers = list(base_model.features)[:-1]
self.base_layers = nn.Sequential(*layers) # block5_conv3 output
self.prelstm = BasicConv(Commom_C, Commom_C, 3,1,1,bn=False)
self.bilstm = nn.GRU(Commom_C, Commom_C/2, bidirectional=True, batch_first=True)
self.lstm_fc = BasicConv(Commom_C, Commom_C, 1, 1, relu=True, bn=False)
self.rpn_class = BasicConv(Commom_C, anchor_k*2, 1, 1, relu=False,bn=False)
self.rpn_regress = BasicConv(Commom_C, anchor_k*2, 1, 1, relu=False, bn=False)
def forward(self, x):
#
# basebone network run
#
x = self.base_layers(x)
#
# Convert feature map to lstm input
#
x = self.prelstm(x)
x1 = x.permute(0,2,3,1).contiguous() # channels last
b = x1.size() # batch_size, h, w, c
x1 = x1.view(b[0]*b[1], b[2], b[3])
#
# BiLSTM
#
x2, _ = self.bilstm(x1)
xsz = x.size()
x3 = x2.view(xsz[0], xsz[2], xsz[3], 256) # torch.Size([4, 20, 20, 256])
x3 = x3.permute(0,3,1,2).contiguous() # channels first
x3 = self.lstm_fc(x3)
x = x3
#
# RPN
#
rpn_cls = self.rpn_class(x)
rpn_regr = self.rpn_regress(x)
rpn_cls = rpn_cls.permute(0,2,3,1).contiguous()
rpn_regr = rpn_regr.permute(0,2,3,1).contiguous()
rpn_cls = rpn_cls.view(rpn_cls.size(0), rpn_cls.size(1)*rpn_cls.size(2)*anchor_k, 2)
rpn_regr = rpn_regr.view(rpn_regr.size(0), rpn_regr.size(1)*rpn_regr.size(2)*anchor_k, 2)
return rpn_cls, rpn_regr
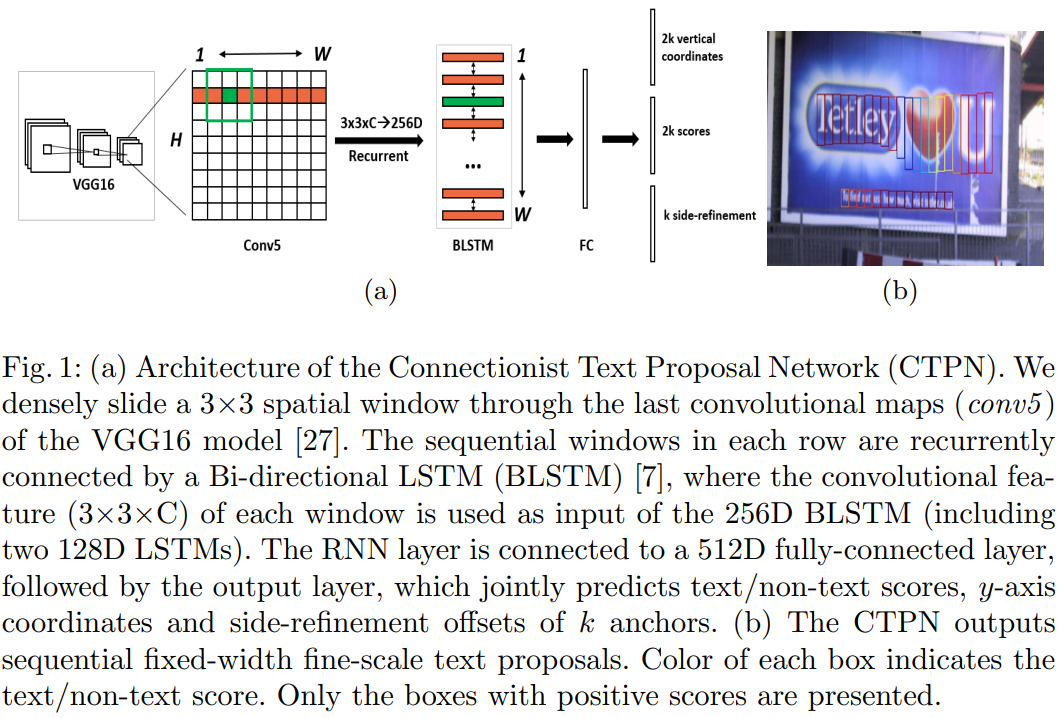
解释一下conv5 feature map如何从\(N\times C
\times H \times W\)变为\(N \times 9C
\times H \times W\) 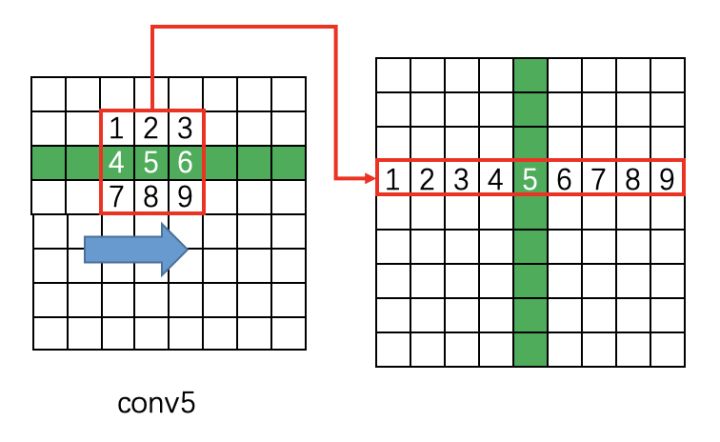
在原版caffe代码中是用im2col提取每个点附近的9点临近点,然后每行都如此处理:
\(H\times W \rightarrow 9 \times H \times W\)
接着每个通道都如此处理: \(C\times H\times W \rightarrow 9C\times H \times W\)
而im2col是用于卷积加速的操作,即将卷积变为矩阵乘法,从而使用Blas库快速计算。到了tf,没有这种操作,所以一般是用conv2d代替im2col,即强行卷积\(C\rightarrow 9C\) 。
再将这个feature map进行Reshape
\[N \times 9C \times H \times W \xrightarrow{\text{reshape}} (NH)\times W\times 9C\]
然后以Batch = NH 且最大时间长度\(T_{max} = W\)的数据流输入双向LSTM,学习每一行的序列特征。双向LSTM输出为\((NH)\times W\times 256\),再经Reshape恢复形状 \((NH)\times W \times 256 \xrightarrow{reshape} N \times 256 \times H \times W\)
该特征即包含空间特性,也包含LSTM学到的序列特征。
然后经过"FC"卷积层,变为\(N\times512\times H \times W\)的特征 最后经过类似Faster R-CNN的RPN网络,获得text proposals.
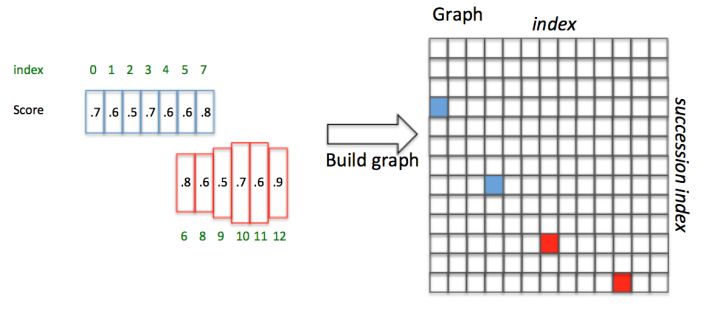
为了说明问题,假设某张图有图9所示的2个text proposal,即蓝色和红色2组Anchor,CTPN采用如下算法构造文本线:
按照水平\(x\)坐标排序anchor 按照规则依次计算每个anchor \(box_i\)的\(pair(box_j)\),组成\(pair(box_i, box_j)\) 通过\(pair(box_i, box_j)\)建立一个Connect graph,最终获得文本检测框
下面详细解释。假设每个anchor index如绿色数字,同时每个anchor Softmax score如黑色数字。
文本线构造算法通过如下方式建立每个anchor \(box_i\)的\(pair(box_i, box_j)\):
正向寻找:
反向寻找:
对比\(score_i\)和\(score_k\):
如果\(score_i \ge score_k\),则这是一个最长连接,那么设置\(Graph(i, j) = True\) 如果\(score_i \lt score_k\),说明这不是一个最长的连接(即该连接肯定包含在另外一个更长的连接中)。
Levenshtein distances9是俄罗斯科学家Vladimir
Levenshtein在1965年发明的,也叫做编辑距离(实际上编辑距离代表一大类算法),距离代表着从s到t需要删、插、代替单个字符的最小步骤数。主要应用:
* Spell checking 检查拼写 * Speech recognition
语音识别 * DNA analysis DNA分析 *
Plagiarism detection 检测抄袭
https://www.jianshu.com/p/56f8c714f372 "自然场景文本检测识别技术综述"↩︎
https://blog.csdn.net/liuxiaoheng1992/article/details/85305871 "SWT博客"↩︎
https://www.cnblogs.com/shangd/p/6164916.html "MSER 博客"↩︎
https://zybuluo.com/hanbingtao/note/541458 "循环神经网络"↩︎
http://colah.github.io/posts/2015-08-Understanding-LSTMs/ "理解LSTM"↩︎
https://www.jianshu.com/p/4b4701beba92 "理解LSTM中文"↩︎
https://arxiv.org/pdf/1610.02357.pdf "Xception"↩︎
https://zhuanlan.zhihu.com/p/34757009 "场景文字检测—CTPN原理与实现" tf code: https://github.com/eragonruan/text-detection-ctpn↩︎
http://www.levenshtein.net/index.html "编辑距离"↩︎
学习深度学习中的一些有意思的东西
物体检测算法概览
编译器中一些不太常用,但是有的时候很有用的options
TF社区中相继出现相关的应用,为了更快的在Pytorch中加入对Volta GPU的支持,并实现针对混合精度训练的优化,NVIDIA发布了Apex开源工具库。cuda9中已经开始支持混合精度训练,tensorRT作为NVIDIA的inference引擎,同样支持混合精度的inference.
物体检测算法的评估方法
最近几年,随着移动互联,物联网的发展,高通赚得盆满钵满。本文主要总结日常工作汇总接触到与高通相关的一些东西。
计算机视觉任务,在训练阶段常在预处理中应用各种各样的操作来提升模型的泛化性与鲁棒性